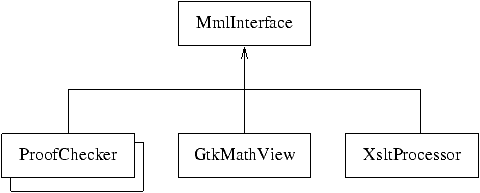
exception ErrorLoadingFile of string
class math_view_signals :
([> `container | `widget | `math_view] as 'b) Gtk.obj ->
object ('a)
method jump :
callback:(string -> unit) -> GtkSignal.id
end
class math_view :
Gtk_mathview.math_view Gtk.obj ->
object
method coerce : GObj.widget
method connect : math_view_signals
method get_selection : string option
method load : filename:string -> unit
end
val math_view :
?adjustmenth:GData.adjustment ->
?adjustmentv:GData.adjustment ->
?border_width:int ->
?width:int ->
?height:int ->
?packing:(GObj.widget -> unit) ->
?show:bool -> unit -> math_view
(* (process filename usecache mode) calls the XSLT *) (* processor on the XML file whose name is filename. *) (* mode could be either "theory" or "cic" *) (* If usecache is true and the result of the processing *) (* is already in cache, then it is reused without *) (* calling again the real XSLT processor. *) process : string * bool * string -> string