Chapter 6 La presentazione delle prove
Al fine di rendere comprensibili le dimostrazioni scritte sotto forma
di l-termini, è necessario affrontare due classi di problemi:
-
Problemi notazionali per le espressioni (tipi):
è necessario effettuare una
``rimatematizzazione'' delle espressioni formali, associando agli
operatori matematici la loro usuale notazione bidimensionale ed
astraendo dalla particolare definizione degli operatori nel sistema
logico, mantenendo però riferimenti precisi ai termini formali.
- Problemi di comprensibilità per le prove (termini):
è necessario associare ai termini che rappresentano prove nel
sistema logico una loro descrizione in linguaggio naturale, con
l'auspicabile possibilità di poter aumentare o diminuire il livello
di dettaglio della prova, fino a giungere al l-termine
sottostante (livello di dettaglio massimo).
Si noti che l'identificazione delle espressioni con i tipi e delle prove
con i termini, pur rappresentando l'essenza della moderna Teoria della
Dimostrazione, è solo approssimativa nei sistemi logici che prevedono
tipi dipendenti, come CIC: in questi sistemi, infatti, i termini e i
tipi sono generati dalla medesima produzione sintattica; ciò nonostante,
è comunque possibile in questi sistemi classificare tutti i
l-termini in livelli, fra i quali quello dei predicati e quello
delle prove, procedendo per ricorsione sulla struttura del termine (si
veda [Wer94]).
Nel prossimo paragrafo viene descritta l'architettura generale
utilizzata in HELM per affrontare entrambe le classi di problemi,
basata sulla tecnologia XSLT; si assume la conoscenza di XSLT da parte del
lettore.
Nel paragrafo 6.2 viene descritto in quale modo sono già stati
affrontati con un buon successo i problemi notazionali in HELM.
Per quanto riguarda la rappresentazione delle prove, come
già spiegato a pagina 8, non esistono attualmente
soluzioni
soddisfacenti; nel paragrafo 6.3 vengono rapidamente illustrate le
idee alla base dei tentativi che verranno effettuati nel successivo sviluppo
del progetto.
6.1 L'architettura generale delle trasformazioni presentazionali
Poiché tutti gli oggetti matematici sono salvati in formato XML
indipendentemente dal formalismo logico in cui sono definiti e in
conformità al prima requisito di HELM, tutte le trasformazioni fra
documenti XML, e in particolare quelle che associano ad un oggetto
la sua presentazione, vengono descritte in XSLT. Poiché ad ogni
formalismo viene associato un differente DTD XML, è richiesto uno
stylesheet presentazionale per ogni formalismo. Inoltre,
al fine di prevedere più di un formato di output e lasciare all'utente
la scelta di quello effettivamente utilizzato, è
richiesto uno stylesheet presentazionale per ogni formato di output.
Al fine di mantenere il numero degli stylesheet lineare nel numero dei
formati di input e output, è necessario adottare un formato intermedio
per disaccoppiare gli stylesheet di backend da quelli di frontend; come
già anticipato nel paragrafo 1.4, MathML content è il candidato
ottimale per questo compito in quanto mette a disposizione un linguaggio
standard per una descrizione semi-formale, ovvero già rimatematizzata,
delle espressioni matematiche.
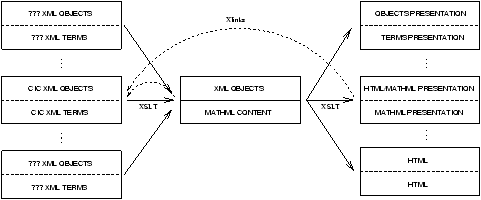
In figura 6.1
viene mostrato lo schema globale delle trasformazioni XSLT.
Figura 6.1: Architettura generale delle trasformazioni presentazionali
I riquadri sulla sinistra indicano i tipi di documenti XML in input,
uno per ogni formalismo logico. Ogni documento prevede due tipi di markup,
quello del livello degli oggetti e quello del livello dei termini; le linee
tratteggiate che li separano nella figura ricordano il fatto che i due markup
sono presenti nello stesso documento e non sono distinti tramite namespace
differenti.
Il riquadro centrale rappresenta il formato intermedio e semi-formale
di rappresentazione dei documenti, già completamente indipendente dal
sistema logico adottato. Per la rappresentazione delle espressioni matematiche
viene utilizzato MathML content, ricorrendo pesantemente all'utilizzo di
csymbol, per esempio per rappresentare i costruttori dei termini di CIC come
Prod o Lambda. Per codificare tutte le informazioni che non sono espressioni
matematiche, è necessario ricorrere ad un secondo tipo di markup XML, che
è in corso di definizione.
Idealmente, grazie alla scelta dello standard
MathML, il formato intermedio può essere utilizzato per esportare
informazioni verso tool per la matematica non formalizzata, come, per esempio,
sistemi per il calcolo simbolico; concretamente, questo diventa impossibile
in assenza dell'associazione di una semantica ai csymbol, la quale potrebbe
essere fornita definendo opportuni content-dictionary OpenMath.
Le frecce solide che hanno come sorgente i sistemi formali e bersaglio il
formato intermedio rappresentano opportuni stylesheet XSLT, che verranno
descritti nel paragrafo 6.2. Poiché ad ogni notazione matematica
corrispondono una o più regole di trasformazione, deve necessariamente
essere previsto un meccanismo che permetta all'utente di combinare assieme
più stylesheet, uno per ogni notazione scelta, prima di applicarli al
documento in input; la soluzione adottata viene descritta nel capitolo
7.
Per associare alle espressioni semi-formali del formato intermedio quelle
formali da cui derivano si ricorre allo standard XLink:
ad ogni elemento XML che è radice di una (sotto)espressione viene aggiunto
un link alla radice della corrispondente (sotto)espressione nel file in input.
Tutti gli XLink specificano lo stesso documento, ma differiscono per
l'XPointer, ovvero la stringa che identifica l'elemento XML all'interno del
file.
Inizialmente, il formato scelto per gli XPointer è stato quello della
descrizione del cammino radice-foglia all'interno dell'albero XML; le altezze
molto elevate degli alberi DOM dei l-termini richiedevano XPointer
di lunghezze risibili, dell'ordine delle centinaia di caratteri per gli
oggetti più complessi. Pertanto, ad ogni elemento XML che possa essere
bersaglio di un XLink è stato aggiunto nel DTD riportato in appendice
A un attributo univoco id di tipo ID.
I riquadri a destra rappresentano i formati di resa per gli oggetti della
libreria, quali HTML, XML, MathML presentation o LATEX. La separazione fra
il livello degli oggetti e quello dei termini può essere completamente
ignorata oppure preservata utilizzando markup di diverso tipo.
Le frecce solide dal formato intermedio a quelli di resa rappresentano
altri stylesheet XSLT. Come per le precedenti trasformazioni, la scelta
dello stylesheet da applicare, cosí come quella del formato di output
desiderato, deve essere lasciata all'utente, grazie ai meccanismi che
descriveremo nel capitolo 7.
Infine, XLink viene utilizzato per associare alla presentazione di una
espressione la sua definizione formale, esattamente nello stesso modo e
con la stessa sintassi già utilizzati per il formato intermedio.
6.2 Gli stylesheet notazionali
Per risolvere i problemi notazionali sono stati scritti alcuni stylesheet
la cui unica finalità è la rimatematizzazione e la successiva resa
dei l-termini:
quando il termine è la codifica di un'espressione matematica per la
quale è stata specificata sotto forma di stylesheet una notazione, questa
deve essere utilizzata; negli altri casi il termine deve essere reso
senza ulteriori trasformazioni, ma adottando un'opportuna politica di
indentazione che ne massimizzi la leggibilità. Concretamente è necessario
fornire:
-
Uno o più stylesheet dal formato CIC a quello MathML content che
descrivano le
trasformazioni di default; ad ogni elemento specificato dal DTD deve
essere associata una trasformazione.
- Un meccanismo che permetta agli utenti di scrivere nuovi stylesheet
dal formato CIC a quello MathML content che descrivano le trasformazioni
particolari associate alle varie notazioni. Durante l'applicazione degli
stylesheet, se nessuna notazione particolare è applicabile ad un elemento,
allora deve essere utilizzata la trasformazione di default. È necessario
fornire un'opportuna politica per la risoluzione di eventuali
conflitti, ovvero i casi in cui ad un elemento venga associata più di una
notazione.
- Uno stylesheet per ogni formato di output che descriva la
trasformazione
dal formato intermedio a quello voluto. Tale trasformazione non è affatto
banale, in quanto è responsabile del layout del documento generato. In
altre parole, è in questa fase che è necessario decidere l'indentazione
del documento, basandosi sulle dimensioni della pagina e sulla semantica
delle formule.
Analizziamo esclusivamente le peculiarità delle soluzioni adottate. Per quanto
riguarda il punto A, sono stati scritti due stylesheet, uno per il
livello degli oggetti e uno per quello dei termini. Il primo, la cui
implementazione non ha presentato difficoltà, essenzialmente
ricopia i tag del livello content aggiungendo gli opportuni XLink al file
sorgente e richiama il secondo quando incontra i corpi e i tipi degli oggetti.
Per quanto riguarda il secondo, l'unica difficoltà è stata l'assenza in
MathML content di tutti gli elementi corrispondenti ai possibili nodi di CIC,
ad eccezione della l-astrazione e dell'applicazione. Per quanto riguarda
quest'ultima, abbiamo preferito non identificarla con quella di CIC; infatti,
l'applicazione di MathML non corrisponde all'usuale applicazione di funzione,
bensí al nodo applicazione negli alberi di sintassi astratta delle
espressioni matematiche. Per esempio, l'espressione n > 0 in MathML
content diventa
<apply>
<gt/>
<ci>n</ci>
<ci>0</ci>
</apply>
dove l'elemento apply non può essere visto come un'applicazione in quanto
l'operatore > non è una funzione, bensí una relazione.
Conseguentemente
abbiamo utilizzato un csymbol per ogni nodo CIC diverso dalla
l-astrazione, compresa l'applicazione; inoltre, sono stati utilizzati
due csymbol differenti per il prodotto dipendente e quello indipendente, che
in CIC è un caso particolare del precedente. Nell'esempio seguente viene
mostrata la regola utilizzata per l'applicazione:
<xsl:template match="APPLY" mode="noannot">
<m:apply helm:xref="{@id}">
<m:csymbol>app</m:csymbol>
<xsl:apply-templates mode="noannot" select="*"/>
</m:apply>
</xsl:template>
Si noti l'introduzione come attributo ``helm:xref'' dell'XLink che
alla radice dell'albero generato dall'elemento APPLY associa il riferimento
a quest'ultimo. Tutte le altre regole dello stylesheet sono essenzialmente
simili.
Per quanto riguarda il punto B, i meccanismi di inclusione, importazione
e controllo della priorità forniti da XSLT sono sufficienti a risolvere
il problema dei conflitti fra notazioni e quindi anche il caso particolare
del ricorso alle regole di default. Il vero problema, quindi, rimane quello
di permettere all'utente di combinare dinamicamente diversi stylesheet
ordinati per priorità crescente in quanto XSLT è, riguardo a questa
esigenza, estremamente carente: l'importazione e l'inclusione di uno stylesheet
all'interno di un altro, infatti, può essere eseguita esclusivamente
in modo statico. La soluzione consiste nella realizzazione di un programma,
integrato nell'interfaccia di accesso alla libreria, che, dato l'elenco degli
stylesheet da combinare, sintetizzi un nuovo stylesheet che includa tutti
quelli dell'elenco; resta, però, il problema di fornire all'utente l'elenco
delle notazioni applicabili, che verrà affrontato nelle fasi successive
con l'introduzione di appositi metadati.
La scrittura degli stylesheet notazionali dal livello CIC a quello content
è un'operazione resa non affatto
banale dalla possibilità di avere applicazioni parziali di funzioni, per
le quali la notazione è spesso non applicabile, e dal meccanismo di cottura
di Coq che rende difficoltosa la distinzione dell'istanzazione dei parametri
delle costanti (ingredienti) dall'applicazione di queste ad argomenti.
Per esempio, quella che segue è la regola per la notazione
``Ï'' per la non-appartenenza insiemistica:
<xsl:template match="
APPLY[
CONST[attribute::uri='cic:/coq/INIT/Logic/not.con']
and (count(child::*) = 2)
and APPLY[CONST[
attribute::uri='cic:/coq/SETS/Ensembles/Ensembles/In.con'
]]
]" mode="noannot">
<xsl:variable name="no_params">
<xsl:call-template name="get_no_params">
<xsl:with-param name="first_uri" select="/cicxml/@uri"/>
<xsl:with-param name="second_uri" select="APPLY/CONST/@uri"/>
</xsl:call-template>
</xsl:variable>
<xsl:choose>
<xsl:when test=
"(count(APPLY/child::*) - number($no_params)) = 3">
<m:apply helm:xref="{@id}">
<m:notin/>
<xsl:apply-templates select="*[2]/*[3+$no_params]"
mode="noannot"/>
<xsl:apply-templates select="*[2]/*[2+$no_params]"
mode="set"/>
</m:apply>
</xsl:when>
<xsl:otherwise>
<xsl:apply-imports/>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
La regola fa match con l'applicazione (totale, due argomenti) della costante
``not'', che non ha parametri, all'applicazione della costante ``In'' ai suoi
argomenti;
la prima operazione compiuta è il calcolo del numero dei parametri
attesi in input dalla costante ``In'' al livello di cottura corrente,
determinato a partire dall'URI del file corrente (``first_uri'') e dall'URI
della costante (``second_uri''). Successivamente viene verificato se
l'applicazione della costante ``In'' è totale o meno (i due argomenti attesi
oltre agli ingredienti
sono, nell'ordine, l'insieme e l'elemento): se la risposta è affermativa si
utilizza la speciale notazione, altrimenti si richiamano le regole di default.
Poiché la scrittura degli stylesheet notazionali dal livello CIC a quello
content è complicata, ripetitiva, prona ad errori e deve essere svolta dagli
utenti che scrivono le teorie, che
tipicamente non sono conoscitori di XSLT, un interessante problema aperto è
quello della possibilità di sviluppare tool semiautomatici per generare gli
stylesheet a partire dalle definizioni degli operatori in CIC e da
descrizioni concise delle notazioni, che possono essere date in modo
testuale o tramite interfacce grafiche.
I problemi legati al punto C, quello della scrittura degli stylesheet dal
livello presentation a quello content, sono dipendenti dalla scelta del
formato di output. Limitandoci al caso della scelta di MathML presentation,
bisogna affrontare la carenza dello standard per quanto riguarda i meccanismi
di layout delle formule che non stiano nella pagina a meno di essere mandate
a capo. Poiché in HELM le prove vengono rappresentate tramite formule, è
frequente ottenere espressioni estremamente complesse e capaci di occupare anche
numerose schermate. Il fatto che usualmente le espressioni utilizzate in
matematica siano molto meno complesse giustifica solo parzialmente la scelta
di non definire meccanismi precisi nello standard: i browser per
MathML presentation non sono nemmeno obbligati a fornire un qualunque
meccanismo. Questa pratica non è affatto sorprendente e riprende la filosofia
di LATEX, in cui le formule vengono spezzate in maniera triviale, lasciando
l'onere all'utente di strutturare le formule complesse tramite l'utilizzo
di tabelle, esattamente come è possibile fare anche in MathML.
Quest'ultima soluzione, però, si presta male all'automatizzazione:
sono stati sviluppati diversi stylesheet per la conversione di MathML content
markup in MathML presentation markup, ma nessuno gestisce l'andata a capo
di formule complesse. I motivi della difficoltà di questa gestione sono
dovuti sia all'impossibilità di sapere quali saranno le dimensioni dei
bounding box di ogni sottoformula, sia alla necessità di conoscere la
semantica dell'espressione della quale si vuole fare il layout per poter
decidere in quali punti spezzarla e quali indentazioni applicare.
Pertanto, è stato necessario scrivere uno stylesheet
di conversione da MathML content a MathML presentation che gestisca il layout
di formule estese e consideri anche i csymbol utilizzati in HELM a livello
content. Lo stylesheet procede a grandi linee in questo modo: ogni volta
che un elemento fa match con una regola, viene stimata la larghezza della
sua rappresentazione e questa viene sottratta alla larghezza residua prima
di terminare la pagina; se il valore ottenuto è positivo la formula
non viene spezzata e le si applica la trasformazione canonica; altrimenti
viene creata una tabella in cui vengono inserite, con un'opportuna indentazione
e procedendo per ricorsione, le rappresentazioni delle sottoformule, calcolate
sottraendo alla larghezza residua della pagina l'indentazione applicata.
Come regole canoniche vengono utilizzate quelle di uno stylesheet scritto
da Igor Rodoniov del Computer Science Department della University of
Western Ontario, London, Canada: un ottimo esempio di riutilizzo del codice
reso possibile dall'adozione degli standard XSLT e MathML.
6.3 Alcune idee per la resa delle prove
Come già anticipato a pagina 8, non esistono
ancora soluzioni
soddisfacenti al problema della difficile comprensibilità delle dimostrazioni
scritte in un sistema formale, anche se è ormai chiaro che l'obiettivo
richiede di fornire almeno una descrizione (iper)testuale in linguaggio
naturale della prova, simile a quelle normalmente presenti nei testi cartacei.
Il valore aggiunto dalle librerie elettroniche rispetto a questi ultimi, oltre
che nella facilità di reperimento delle informazioni, consiste
nell'ipertestualità del documento e nella possibilità di avere diversi
livelli di dettaglio per le prove, da quello iperdettagliato del termine
formale a quello altamente non informativo dell'omissione della prova
(``Dimostrazione: ovvia''). Inoltre, personalmente ritengo che un ulteriore
valore aggiunto consista nella possibilità, da parte dell'utente, di poter
``annotare'' la descrizione con propri commenti, esattamente come
normalmente avviene nel mondo cartaceo, ma con una potenza espressiva molto
maggiore data dall'ipertestualità.
Fino ad ora i soli approcci in corso di sperimentazione sono quelli della
sintesi automatica della descrizione naturale a partire o dalla prova formale
o dalla sequenza di tattiche applicate1.
Come già mostrato a pagina 2.3.2, tale approccio è
insoddisfacente, ma il risultato ottenuto è un'ottima base di partenza per
una successiva (ri)annotazione della prova. Per questo motivo, nell'ambito
del progetto HELM è in corso di scrittura un sistema di stylesheet per
la generazione automatica della descrizione in linguaggio pseudo-naturale
delle prove. Nel paragrafo 6.3.2 vengono descritte le
problematiche
che si dovranno affrontare seguendo questo approccio; nel prossimo paragrafo,
invece, viene proposta una nuova soluzione alternativa.
6.3.1 Le annotazioni
A mio avviso, un modo per superare i limiti dell'approccio basato sulla
sintesi automatizzata consiste
nell'utilizzo di annotazioni strutturate intese non solo come
note e commenti aggiunti alla descrizione, ma viste come la descrizione stessa
in linguaggio naturale dei termini. Concretamente, la mia proposta consiste
nella possibilità di associare ad ogni nodo di un termine CIC una annotazione
scritta in XML. Il contenuto dell'annotazione consiste di due tipi di markup
distinti, quello di output per la descrizione di testo e formule matematiche
e quello di ricorsione i cui elementi sono riferimenti agli attributi del nodo
corrente, riferimenti ad altri nodi o uno speciale elemento che indica la
descrizione formale del nodo corrente. Per effettuare la resa delle prove
è necessario
fornire un nuovo stylesheet che compia ``ricorsivamente'' la seguente
operazione a partire dalla radice dell'albero:
-
Se il nodo corrente è privo di annotazione, richiama la regola
opportuna dello stylesheet per i termini non annotati, ovvero quello per
la resa del l-termine.
- Altrimenti itera su ogni elemento dell'annotazione in questo modo:
-
Se incontri un elemento del markup di output, ricopialo.
- Se incontri un riferimento ad un attributo del nodo corrente, stampa
il valore dell'attributo.
- Se incontri l'elemento che indica la descrizione formale del nodo
corrente, richiama la regola opportuna dello stylesheet per i termini
non annotati.
- Se incontri un riferimento ad un altro nodo, processa con la regola
più esterna il nodo puntato.
Si osservi che, se l'annotazione di un nodo non contiene riferimenti ad
altri nodi, al termine della stampa del markup di output la funzione
termina. Quindi, per esempio, se il nodo radice ha come annotazione
esclusivamente il markup di output contenente la stringa ``Ovvio'',
allora la resa complessiva del termine sarà tale stringa e tutti gli
altri nodi dell'albero non saranno visitati.
Nonostante l'algoritmo sia già stato interamente specificato, il formato
dei riferimenti è ancora imprecisato e determina il grado di fedeltà
della descrizione in linguaggio naturale al l-termine. In particolare,
se tutti i possibili riferimenti sono ammessi, allora la resa del termine
può avvenire distruggendo la struttura del termine e visitandone i nodi
in un qualsiasi ordine. Al contrario, se ogni nodo può riferire
esclusivamente i propri figli, l'albero delle annotazioni non può essere
che isomorfo ad un sottoalbero di quello del termine, a meno dell'ordine
relativo fra i figli di uno stesso nodo e con il vincolo aggiuntivo che
le due radici siano in relazione fra loro. Nonostante la seconda soluzione
sembri decisamente più attraente, i primi esperimenti compiuti indicano
che la resa migliore si ottiene utilizzando vincoli intermedi, che permettano
esclusivamente alcune riorganizzazioni dell'albero di partenza: per esempio,
è una buona scelta anticipare la descrizione degli argomenti di una
applicazione prima dell'applicazione stessa quando questi siano prove non
atomiche di proposizioni e la funzione applicata sia la prova di una
implicazione, come nel caso seguente:
Siano transXYZ e transX0Y due istanze della prova della proprietà
transitiva della relazione ``>'', rispettivamente di tipo
(X>Y) ® (Y>Z) ® (X>Z) e
(X>0) ® (0>Y) ® (X>Y),
e siano
P una prova di (X>0), N una prova di (0>Y) e H una prova di (Y>Z).
La dimostrazione (transXYZ (transX0Y P N) H) della tesi (X>Z)
viene normalmente resa come:
``Per la proprietà transitiva transX0Y applicata alle ipotesi P e
N si ha X>Y. Da qui, per la proprietà transitiva transXYZ e
l'ipotesi H, si ha la tesi.''
La precedente descrizione viene facilmente ottenuta ricorrendo alle seguenti
annotazioni:
-
Applicazione più esterna:
-
``<<riferimento all'applicazione più interna>>
Da qui, per la proprietà transitiva
<<riferimento al primo figlio della funzione>> e
l'ipotesi
<<riferimento al terzo figlio della funzione>>, si
ha la tesi.''
- Applicazione più interna:
-
``Per la proprietà transitiva
<<riferimento al primo figlio della funzione>> applicata
alle ipotesi
<<riferimento al secondo figlio della funzione>> e
<<riferimento al terzo figlio della funzione>> si ha
X>Y.
La soluzione basata sulle annotazioni è suscettibile di due critiche:
-
Non vi è alcuna garanzia che l'annotazione di un nodo corrisponda
alla descrizione informale e corretta del nodo stesso.
- Poiché annotare un termine è tanto difficile quanto capire la
prova formale, annotare termini di grosse dimensioni è impraticabile.
Pur essendo la prima critica sicuramente valida, l'unica garanzia
sulla corrispondenza fra la descrizione informale e quella formale verrebbe
dalla generazione automatica della prima a partire dalla seconda, procedura
che è insoddisfacente, almeno rispetto all'attuale stato dell'arte.
Pertanto, l'idea di utilizzare le annotazioni è giustificata dal seguente
compromesso:
la provabilità dei teoremi annotati non è messa in discussione, in quanto
è sempre possibile richiamare un proof-checker sul sottostante termine
formale, mentre la garanzia della correttezza della prova che viene letta
è sacrificata alla sua leggibilità. Si noti che, in ogni caso, il
vantaggio rispetto alle prove cartacee è notevole: innanzi tutto per queste
non viene garantita nemmeno la provabilità della tesi; inoltre, nel caso
che venga trovato un errore in una prova, nel caso cartaceo è necessario
cercare una nuova prova ripartendo da zero, mentre nel caso delle annotazioni
è sufficiente deannotare il (sotto)termine male annotato e riannotarlo con
la descrizione corretta (che esiste sempre!) del termine formale sottostante.
Il problema messo in luce dalla seconda critica è reale, ma può essere
affrontato in molteplici modi. Innanzi tutto, come abbiamo potuto sperimentare
realizzando un piccolo prototipo di un'interfaccia grafica per l'ausilio
all'annotazione, una buona interfaccia, che permetta di selezionare
interattivamente il sottotermine da annotare e che metta a disposizione una
palette con gli elementi del markup di ricorsione, è sufficiente a rendere
agevole un'operazione altrimenti complessa e prona ad errori. Inoltre,
è possibile ripensare ai tool per la generazione automatica delle descrizioni
in linguaggio formale delle prove come a dei tool per la generazione automatica
delle annotazioni. In questa ottica, il problema di innaturalezza dei prodotti
di questi tool scompare grazie alla possibilità di riannotare manualmente
le descrizioni seguendo la traccia proposta e intervenendo esclusivamente
sulle parti troppo prolisse, troppo artificiali o poco intuitive.
Infine, è ragionevole pensare
che sia possibile scrivere proof-assistant che, ad ogni passo della
dimostrazione, ovvero ad ogni applicazione di una tattica, permettano
all'utente di inserire la descrizione informale del ragionamento effettuato,
salvandola come annotazione del nodo radice del termine generato dalla
tattica2. Il principale vantaggio di questa ultima soluzione consisterebbe
nell'esatta corrispondenza fra l'annotazione e il ragionamento effettuato
e l'eliminazione del problema della comprensione del termine formale per
poterlo riannotare; d'altro canto, la corrispondenza che si instaurerebbe fra
l'uso di una tattica e la scrittura dell'annotazione costringerebbe a
presentare le prove nella stessa maniera con cui vengono cercate, ovvero
quella top-down, mentre diversi secoli di pratica matematica ci hanno insegnato
che il modo migliore di presentare le dimostrazioni è tipicamente quello
bottom-up.
6.3.2 La generazione automatica delle annotazioni.
In questo paragrafo vengono rapidamente presentati i problemi che si incontrano
cercando di realizzare tramite stylesheet XSLT un generatore automatico di
descrizioni in linguaggio naturale a partire dai l-termini della
libreria di HELM3. In quello che segue, si
assumerà che il prodotto della trasformazione sia un'annotazione, nel senso
del precedente paragrafo; pertanto, si può immaginare che lo stylesheet venga
comunque applicato off-line, potendo quindi essere computazionalmente costoso,
e inoltre che non venga richiesto un output particolarmente raffinato grazie
alla possibilità di riannotare la descrizione.
Il principale problema da affrontare è la mancanza nel l-termine
di parte dell'informazione necessaria per una buona resa, ovvero quella
relativa ai tipi e talvolta alle sort di alcuni sottotermini, come si può
vedere nell'esempio precedente a pagina 111:
la formula X>Y inserita manualmente nell'annotazione dell'applicazione
più interna corrisponde al tipo, non disponibile, di tale applicazione
; il problema si presenta ogni volta che bisogna
effettuare la resa di termini contenenti nodi applicazione di sort
Prop.
Un secondo esempio in cui sarebbe necessario conoscere la sort di un termine
è quello della resa dei prodotti dipendenti: se la sort del prodotto è
Prop, allora la sua resa appropriata è come quantificatore
universale.
Nonostante le precedenti informazioni mancanti siano sintetizzabili a partire
dal l-termine ricorrendo alla type-inference, tale operazione è troppo
onerosa da compiere in uno stylesheet, sia dal punto di vista della
complessità implementativa che da quello puramente prestazionale: un
primo prototipo incompleto per CIC, ottenuto reimplementando in XSLT
parte del codice OCaml del proof-checker, ha richiesto circa 1100 linee
di codice e richiede diversi minuti per la sintesi dei tipi mancanti in
l-termini di piccole dimensioni. La soluzione più semplice
consisterebbe nell'aggiungere ai file XML tali tipi direttamente in fase
di esportazione, contravvenendo pesantemente al principio di minimalismo
e diminuendo le prestazione del proof-checker. Una soluzione simile, ma
esente dai precedenti problemi, consiste nell'esportare tali tipi in un
secondo file, che deve essere già considerato un file di annotazioni;
pertanto, nessuna garanzia viene fornita sul suo contenuto, che non viene
cosí esaminato dal proof-checker. Infine, una terza soluzione consiste
nel far richiamare allo stylesheet un motore di type-inference esterno,
implementato in un qualunque linguaggio. Tale soluzione potrebbe risultare
la migliore, ma non esiste purtroppo alcuno standard per permettere ad
uno stylesheet di invocare un programma esterno4.
Un altro importante problema, che dovrà essere affrontato e che è
un'istanza di quello più generale che si avrà con qualsiasi tipo di
annotazione, consiste nell'individuazione del livello, content o
presentation, al quale sostituire le annotazioni ai termini formali.
Attualmente, entrambe le soluzioni possibili non sono soddisfacenti:
utilizzare le annotazioni solamente al livello presentation costringe
ad avere più di una annotazione per ogni file, una per ogni possibile
formato di output, e in questo modo verrebbe calcolata la rappresentazione
a livello content di termini che non saranno successivamente mostrati a
livello presentation. Inoltre, dal momento
che la prima fase di trasformazioni corrisponde concettualmente alla
rimatematizzazione del documento, sembrerebbe più corretto applicare
a livello content le annotazioni, che rappresentano una possibile
rimatematizzazione informale delle prove. Questa soluzione, però,
costringerebbe ad utilizzare come markup di output per le annotazioni
un linguaggio di descrizione del documento compilabile in ogni possibile
formato di output, ovviamente non permettendo di sfruttare le potenzialità
di questi. Inoltre, in questo modo, elementi del content markup di MathML
potrebbero avere come figli elementi del markup di output, contravvenendo
alle specifiche di MathML: infatti, affinché il content markup
possa essere utilizzato per lo scambio di dati fra applicazioni che utilizzano
MathML, è necessario che la semantica delle espressioni
scambiate sia univoca, almeno in assenza di csymbol; questa proprietà
non sarebbe ovviamente rispettabile utilizzando all'interno del termine markup
estraneo, privo di semantica.
Ora, alla luce delle precedenti osservazioni, non è possibile escludere
un ridisegno dell'architettura complessiva delle trasformazioni XSLT, con
l'aggiunta di eventuali livelli intermedi fra quello content e quello
presentation. Nel frattempo, però, si è notata la possibilità di
fattorizzare la trasformazione compiuta dal generatore automatico di
annotazioni in due fasi: la prima prevede la riorganizzazione della struttura
dell'albero di prova, per esempio al fine di anticipare le prove dei risultati
parziali, ed è legata al markup di ricorsione; la seconda sostituisce i
termini formali con il markup di output. Mentre non è ancora chiaro se
e come queste due fasi possano corrispondere al livello content e a quello
presentation, è immediato notare che il primo tipo di trasformazione
non altera il contenuto informativo delle prove e può essere internalizzata
nel sistema logico a cui venga aggiunto un operatore di naming, usualmente
chiamato ``let ... in'': alla produzione sintattica
per i termini di CIC viene aggiunto il costrutto
let r = t1 in t2 dove r è un identificatore e
t1 e t2 sono termini; let r = t1 in t2 è ben
tipato quando t2[t1/r] è tale e in questo caso ha lo stesso tipo; infine
viene introdotta un nuovo tipo di conversione =let, simile
all'a-conversione e chiamata let-conversione,
definita da (let r = t1 in t2) =let t2[t1/r].
In questo modo l'operazione di riorganizzazione dell'albero di prova
corrisponderebbe semplicemente alla sua sostituzione con un altro albero ad esso
let-convertibile.
La precedente osservazione è particolarmente interessante in quanto
l'operatore di naming, nonostante sia logicamente irrilevante5, può
contribuire pesantemente all'aumento della leggibilità delle dimostrazioni
e può essere utilizzato per diminuire notevolmente le dimensioni dei
l-termini in cui uno stesso sottotermine compaia più volte.
In particolare, quest'ultima proprietà e la frequenza della sua
applicabilità hanno spinto il team di Coq
ad aggiungere l'operatore a CIC nella nuova versione del proof-assistant
attualmente in sviluppo.
Infine, come per le trasformazioni notazionali, il meccanismo di generazione
automatica dovrà essere estendibile per permettere agli utenti di associare
ai principi di eliminazione dei nuovi tipi (co)induttivi un'opportuna
descrizione in linguaggio naturale. Per esempio, l'applicazione del principio
di eliminazione sui numeri naturali potrà essere trasformata nella locuzione
``Procediamo per induzione su .... Caso base: ...Passo induttivo: ...'', mentre quello di eliminazione del tipo induttivo
``or'' potrà diventare ``Procediamo per casi. Se è vero ...allora ...altrimenti ...''.
6.4 Risultati ottenuti.
Dai membri del progetto HELM sono già stati sviluppati numerosi stylesheet
notazionali, dei quali riportiamo a titolo indicativo le dimensioni in
numero di linee di codice e numero di file in cui queste vengono strutturate:
| CIC ® content |
| Trasformazioni di default dal livello CIC a quello content, comprendenti
anche il livello dei termini |
7 stylesheet, 819 linee |
| Trasformazioni dal livello CIC a quello content per le notazioni relative
alle operazioni insiemistiche, logiche e sui numeri reali |
3 stylesheet, 1017 linee |
|
| content ® presentation |
| Trasformazioni con output MathML presentation dal livello content a
quello presentation dei soli elementi prodotti dai precedenti stylesheet;
sono escluse le trasformazioni canoniche |
3 stylesheet, 1052 linee |
| Trasformazioni con output HTML dal livello content a quello presentation
dei soli elementi prodotti dalle trasformazioni di default dal livello
CIC a quello content |
1 stylesheet, 657 linee |
| Trasformazioni con output HTML dal livello content a quello presentation
dei soli elementi prodotti dalle trasformazioni per le notazioni relative
alle operazioni insiemistiche, quelle logiche e quelle sui numeri reali |
3 stylesheet, 956 linee |
|
Riportiamo, inoltre, le dimensioni dello stylesheet scritto da Igor Rodoniov
e richiamato dalle trasformazioni di default dal livello content a quello
presentation:
| Trasformazioni canoniche da MathML content a MathML presentation |
1 stylesheet, 1848 linee |
Per quanto riguarda la resa delle prove, non si hanno ancora risultati
definitivi, ma si sta lavorando sia sul fronte
dell'annotazione manuale, costruendo un'interfaccia prototipo, sia su quello
della generazione automatica, scrivendo opportuni stylesheet. L'interfaccia,
ancora decisamente grezza per quel che riguarda l'ausilio all'annotazione,
viene descritta nel paragrafo 7.2. Descriviamo ora brevemente la
soluzione adottata per la generazione automatica.
Il primo problema affrontato è stato quello della sintesi
dei tipi mancanti. Come esperimento, è stato scritto dal Prof. Asperti
uno stylesheet, ancora ampiamente incompleto, che effettua la sintesi e produce
in output un file XML contenente la lista dei tipi sintetizzati con il
riferimento all'elemento XML del nodo CIC a cui il tipo si riferisce. Come era
lecito attendersi dal fatto che, mediamente, circa la metà dei nodi di
un l-termine sono applicazioni il cui tipo deve essere sintetizzato,
l'applicazione dello stylesheet a termini di medie dimensioni
richiede diversi minuti e genera file le cui dimensioni sono le stesse o di
poco inferiori rispetto a quelle del file sorgente.
Conseguentemente, visti gli alti tempi di elaborazione
e le dimensioni tollerabili dei file generati e considerato che l'immutabilità
dei file XML comporta l'immutabilità dei file sintetizzati, si è deciso di
effettuare la sintesi dei tipi in maniera off-line, subito dopo l'esportazione
da Coq. Inoltre, viste le scarse prestazioni della sintesi in XSLT e poiché
non vi è alcun motivo che la faccia preferire a quella scritta in un altro
linguaggio, questa verrà probabilmente rimpiazzata o affiancata da un'analoga
implementazione in OCaml.
Il secondo problema consiste nella scrittura dei due stylesheet, uno dal livello
CIC a quello content e l'altro da questo a quello presentation, che utilizzino
i tipi sintetizzati per generare la resa in linguaggio naturale del termine.
Si noti che, per il momento, l'output del processo non è un'annotazione come
ipotizzato nel paragrafo 6.3.2, ma è già la resa definitiva.
Affinché
lo stylesheet possa processare contemporaneamente due file XML, è necessario
applicarlo ad uno dei due e utilizzare la funzione XSLT ``document'' che
permette di caricare un secondo file e ne restituisce il nodo radice. A causa
di una limitazione dello standard XSLT 1.0, che verrà eliminata nella
versione 1.1, non è possibile invocare la funzione
``document'' una volta sola, memorizzandone il risultato in una variabile per
poterlo riutilizzare successivamente, costringendo a ripetute
invocazioni6. In teoria, tali
invocazioni ripetute non dovrebbero essere computazionalmente costose, in quanto
lo standard prescrive che due invocazioni distinte della funzione ``document''
aventi come parametro lo stesso URI ritornino la stessa copia del documento
scaricato. In realtà, tutte le implementazioni disponibili, uniformandosi
alle regole per il caching utilizzate nei browser HTML, riscaricano il documento
ogni volta nel caso che l'URI sia un URL che punti ad un contenuto dinamico,
ovvero, per esempio, contenente passaggio di parametri secondo il metodo HTTP
post. Questa caratteristica, nonostante non sia conforme allo standard, è
estremamente utile in quanto consente di utilizzare lo stratagemma descritto
nella nota 4 a pagina 114.
Nel caso di HELM, tutti i
documenti vengono richiesti al getter con interfaccia HTTP e sono quindi
riconosciuti come dinamici; come conseguenza, non è possibile per motivi
prestazionali invocare ripetutamente la funzione ``document''. Invece di
ricorrere all'estensione proprietaria del processore XSLT per trasformare
i result tree fragment in node set, abbiamo preferito aggiungere
all'implementazione del getter con interfaccia HTTP la quarta funzionalità
opzionale descritta a pagina 74, ovvero la possibilità di
effettuare sintesi di documenti XML a partire da fonti distinte. Concretamente,
è stato aggiunto al getter un nuovo metodo che, ricevuti in input gli URI
di un oggetto CIC e del file contenente i relativi tipi sintetizzati, costruisce
un nuovo documento XML ottenuto creando un nuovo nodo radice avente come figli
le radici dei due documenti.
Non descriveremo in questo lavoro gli algoritmi implementati nei due stylesheet
in quanto questi non sono ancora terminati e saranno presto sottoposti ad una
riorganizzazione complessiva.
Concludendo, nonostante, una volta introdotta la generazione automatica delle
descrizioni in linguaggio naturale, i risultati visivi ottenuti siano
soddisfacenti, deve essere svolto ancora molto lavoro per rendere
l'architettura complessiva degli stylesheet pulita ed estendibile.
- 1
- Si vedano rispettivamente
il modulo Natural di Coq [CKT95] e quello Proverb di Omega
[Hor99].
- 2
- L'operazione non è semplice come può sembrare a prima
vista in quanto esistono tattiche che compiono trasformazioni complesse
sul l-termine. Inoltre, l'implementazione più semplice di una tattica
non si preoccupa mai della verifica che il termine generato sia il più
naturale possibile, prediligendo la facilità implementativa, ma generando
termini ingiustificatamente complessi, che vengono talvolta successivamente
semplificati, per esempio procedendo all'eliminazione di alcuni dei tagli
introdotti.
- 3
- Le osservazioni derivano in larga parte dallo
studio del Prof. Asperti che, nell'ambito del progetto HELM, sta realizzando
un primo prototipo di generatore automatico.
- 4
- Lo
standard XSLT 1.0
prevede l'implementazione di funzioni di estensione, ma non specifica alcuno
standard per l'interfacciamento di tali funzioni con il processore XSLT. Lo
standard XSLT 1.1 affronterà il problema, ma non sarà disponibile che fra
diversi mesi. Ciò nonostante, esiste già ora un modo non ufficiale, ma
funzionante con ogni processore, per ottenere un risultato analogo:
la scrittura della funzione come metodo di un HTTP server o come CGI.
Il getter descritto nel paragrafo 4.1.2 utilizza esattamente tale
stratagemma.
- 5
- Nella
particolare formulazione proposta.
- 6
- Più dettagliatamente, le variabili possono memorizzare
result tree fragment (rtf), ovvero alberi XML come quelli restituiti
dall'applicazione dell'istruzione ``value-of'' ad un XPath contenente
l'invocazione della funzione ``document''; quello che non si può fare è
applicare funzioni XPath agli rtf, impedendo quindi la selezione di nodi
dell'albero memorizzato nell'rtf. Nella prossima versione dello standard
quest'ultima limitazione verrà semplicemente eliminata; attualmente,
comunque, tutti i processori XSLT implementano come estensione proprietaria una
funzione che trasforma un rtf in un node set, sul quale è possibile applicare
funzioni XPath. Per poter scrivere lo stylesheet per la sintesi automatica,
più dettagliatamente per poter implementare la funzione di sostituzione, è
stato necessario ricorrere ad una di tali estensioni.