The Hypertextual Electronic Library of Mathematics
Main Projectual Provisos
The next, compelling step for every tool
aimed at the automation of formal reasoning and
the mechanization of mathematics is its integration
with (and exploitation through) the World Wide Web.
This simple statement borrows already a few major
methodological provisos:
- Standardisation
By standardisation, we only mean the representation of the information
in a clearly defined, application independent format. We have no
foundational ambition, and do not aim to impose our solution.
XML, which is rapidly imposing
as a pivotal technology in the future development of
all internet applications, and the main tool for
representation, manipulation, and exchange of structured information
in the networked age, looks as a natural, almost mandatory tool
to be used in the encoding. Special dialects of XML, such as
MathML can be reasonably used as a standardisation language
for presentational and notational aspects of the information.
- DistributionThe Library must be distributed.
The overall policy must be as liberal as possible, respecting
the general philosophy of the Web: everybody
with a web or ftp space should be allowed to publish its piece
of theory.
- SimplicityThe kernel system should be as light as
possible, and try to profit of all existing technology for
web-publishing and displaying already existing on the market.
It should be conceived as an open system, in the most
general sense of the term. It should be possible to
add more functionalities and utilitites with a minimal effort
and no impact on the kernel.
Current tools are often conceived as more or less monolitich
architectures. To extend the system you are forced to use
the utilities offered by the system itself, with obvious
limitations.
Markup and semantic components
The kernel system is only meant to support
the basic management of mathematical documents
through their lifespan, but in order to support
additional functionalities the intelligence encoded
in the markup should cover all potential uses
to which such documents will be put. To this aim, we
must clearly identify all semantic components of a
typical mathematical document and classifying them
into logical categories (content, structure,
presentation, notation, metadata, \dots). As
a main methodological assumption, we try to keep
a clear distinction between all these components,
as far as possible. Similarly, we aim to reuse all
existing technology and recommended standardization
formats (such as MathML or RDF) for representing and
modeling suitable parts of the information.
We have already identified the following main components:
- low level structural information. This reflects both the
fine grane structure of mathematical expressions and
proofs. This level does usually strictly depend on the
particular formalism adopted. There is little hope to have
a uniform language at this level.
- high level structural information. This level reflects
the organization of mathematical documents as a structured
collection of atomic results. Good hope to reach some
consensus on a common representation. Still, the
distinction between lemmas, propositions, facts, theorems,
etc. (if any) is far from clear.
The relevance of standardisation at this level is mainly related
to the possibility to add relevant metadata in a uniform way.
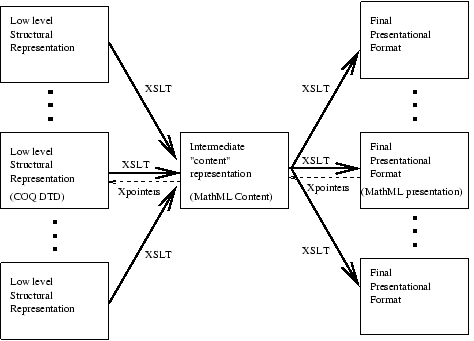
- basic "content" information. The low level structural
information can be translated via a set of XSLT rules in an
intermediate language more suited to be directly published
in a human readable format. This look particularly important
for portability reasons. The content part of MathML
looks as a good candidate as target language. We need
backwards pointers to the low level representation, in form of
xpointers.
Similarly, content is supposed to be transformed in a
format suited to presentation by a further XSLT transformation.
Such a transfromation form content to presentation for
MathML has been already defined (add reference). Again,
we need backwards pointers to content.
In conclusion, for browsing purposes, we shall essentially need
a gtk widget able to interpret MathML presentational tags, that looks
quite feasible (again, something already exists).
- annotations information. This is meant as a natural language
annotation for proof, and it has to be integrated wwith the low
structural level (or intermediate content level), typically during
interactive editing.
- notational and stylistic information. This is to be integrated
with the low level (or intermediate level) to give a precise
description of the intended output. Notation and stylistic
information is mainly intended for expressions (not proofs).
Both annotations and notations are supposed to be used as
user defined "macros" extending and integrating the original set of
XSLT transformations to get the desired presentation.
- metadata. We could distinguish between two kinds of metadata:
intrinsic and extrinsic. By intrinsic metadata we mean all those
information wich can be automatically recovered by the structured
representation of the terms and proofs (such as, say, the list of
identifiers occurring in a term, or the main identifier in the
conclusion of a statement). As a methodological assumption,
intrinsic metadata will not be covered in the kernel system.
Anybody is free to extract them, whenever required.
Extrinsic metadata are all those auxiliary data which cannot
be inferred by the information itself (such as the name of
the author, the date, or a list of keywords). Extrinsic
metadata must be explicitly modeled. They concerns both
level of structural information.
Figure 1:
A DTD for COQ
For our development, we have
adopted COQas a
paradigmatic example of a typical logical framework.
The first phase of HELM has been centered on the problem
of exporting coq objects into XML format.
This has already an interest in its own, for at least three
reasons:
-
Exporting from Coq internal representation to an open representation, such
as XML, will make the libraries survive system Coq when one day it will be
outpassed. This is important because a lot of theories developed in old
proof checkers are now unuseful only because they were stored in internal
representations that are now unreadable.
-
The existing libraries of Coq are a good starting point for developing
new theories. They are also an interesting challenge for a brand new
typechecker for the Calculus of (Co)Inductive Construction.
-
Coq has a powerful, but not yet well explored, system of sections that
make possible to develop new theories defining their axioms and then
use them from other theories instatiating the axioms (that
behave like variables). This is an interesting idea, but in our opinion
the actual implementation of Coq does not exploit it well. An extension
of the theory of cic that would include also sections as ``first class
objects'' looks feasible and really very interesting.
What should NOT be exported from Coq?
Not all information useful to Coq should be exported. In particular we have
choosed not to export:
-
Parsing and pretty-printing rules and information
-
Parsing rules should depend only on the proof engine. To be able to
use other proof engines different from Coq we need not to rely on Coq's own
rules. Similarly, pretty-printing rules should depend only on the browser.
- Tactics-related information
-
This, too, are proof engine dependent.
- Redundant information added by Coq to the terms of cic
-
Coq adds in several places a lot of information to cic terms in order to
fasten the type-checking. This information is clearly redundant, is
unuseful for browsing and could be unuseful also for other type-checkers.
What should be exported from Coq?
The following Coq objects are exported:
-
Constants (definitions/theorems/axioms)
-
Constant objects of Coq are used to represent definitions, theorems and
also axioms. Definitions and theorems are syntactically identical and have
a body and a type. The only difference is semantical: theorems are usually
opaque (only their type is used in cic terms) because of proof-irrelevance,
while definitions are transparent (their body is substituted in their
occurrences in other terms during type checking). Axioms, instead, are
constants with a type but without a body. We choose, during extraction,
to discriminate only axioms from definitions and theorems, that become
undistinguishable once extracted. We suppose that there will exist another
level (a semantical one) responsible of ``marking'' non axiom constants as
theorems, definitions, lemma, facts, ...
Due to the sectioning machinery of Coq, constants defined inside
a section are found in the environment many times: once in the uncooked
form and once for each section in their section path. We choosed to export
a constant in its uncooked form, but adding informations (the list of
variables on which it depends) gotten from the most cooked form.
- Variables
-
Variables have only a type and not a body. A variable behaves like an
axiom inside the theory where it is defined and as a parameter when
using that theory.
- (Co)Inductive Definitions
-
In Coq, you can define also blocks of mutual (co)inductive definitions.
Each definition inside such a block has a name, a type (also called
arity in Coq) and a possibly empty list of constructors. Each
constructor has a name and a type. A simple example is the inductive type
of naturals whose name is nat, whose type is Set and whose
constructors are O of type nat and S of type
(nat -> nat). Blocks, as constants, could depend on variables;
the
list of variables (parameters) on which all the definitions in the block
depend is also exported from Coq.
- Proof in progress
-
We choosed also to export unterminated proofs. As terminated theorems,
an unterminated proof has a name, a type and a body; moreover, it has also
a list of conjectures on which the body depends. Each conjecture has a type
but not a body: to end the proof you must provide a body
for each conjecture.
Sections and cookings in Coq
In Coq it's possible to use sections. To make a section, you must open it,
fill it and then close it. Filling a section means declaring in it other
objects, i.e. variables, constants, local definitions, mutual (co)inductive
types or subsections. So the structure describing sections and subsections in
Coq is naturally a tree.
The names given to objects in the current environment must ever be unique:
for example, if in a supersection an axiom A is defined, you can't
define another one in the current section. When you close a section, though,
all the variables and the local definitions defined in it are discharged and
all the constants and (co)inductive definitions in it are cooked, i.e.
lambda-abstracted with respect to all the discharged variables (ingredients)
that are used, directly or indirectly, inside their bodies. The body of a
local definition, instead, is substituted to all the references to it inside
each cic term of a not-discharged object. Example:
Section a.
Variables V1,V2 : Prop.
Axiom A1 : V1 -> V2.
Axiom A2 : (P:Prop)P -> V1.
Local Apply := [x:V1->V2][y:V1](x y).
Theorem T : (P:Prop)P -> V2.
Exact [P:Prop ; H:P](Apply A1 (A2 P H)).
Qed.
End a.
After End a. the variables V1 and V2 and the local definition
Apply are discharged. The other objects become equal to the ones defined,
without using sections, in this way:
Axiom A1 : (V1,V2:Prop)V1 -> V2.
Axiom A2 : (V1,P:Prop)P -> V1.
Theorem T : (V1,V2,P:Prop)P -> V2.
Exact [V1:Prop ; V2:Prop ; P:Prop ; H:P](A1 V1 V2 (A2 V1 P H)).
Qed.
Note that A2 is abstracted only w.r.t. V1 because it doesn't
depend on V2 and that T is abstracted also w.r.t. V1
on which it depends only implicitly through A1 and A2.
In order to improve performance, Coq implementation of cooking is not uniform
on all the objects:
-
Objects that are thought to be used often, i.e. inductive definitions and
``destructor'' functions on inductive definition (the ones ending in
``ind'', ``rec'' and ``rect'') are replaced with the
cooked ones: this is the trivial implementation.
-
Other constants (all the definitions, axioms and functions that
are not destructors of inductive definition) are replaced with
recipes. A recipe is a pointer to an uncooked term or to another
recipe plus an ordered list of ingredients and some other information.
During type-checking, every time an expression (Apply R P1 ... Pn)
is met where R is a recipe whose content is R' and whose list of
ingredients is P'1 ... P'm with m < n, then the expression is
reduced to (Apply R'[P1/P'1 ... Pn/P'n] Pm+1 ... Pn).
The DTD
Here is the current draft of a DTD for the low level structure of
Coq term
<?xml encoding="ISO-8859-1"?>
<!--*****************************************************************-->
<!-- DTD FOR CIC OBJECTS: -->
<!-- First draft: September 1999, Claudio Sacerdoti Coen -->
<!-- Revised: February 3 2000, Claudio Sacerdoti Coen, Irene Schena -->
<!--*****************************************************************-->
<!-- CIC term declaration -->
<!ENTITY % term '(LAMBDA|CAST|PROD|REL|SORT|APPLY|VAR|META|IMPLICIT|CONST|
ABST|MUTIND|MUTCONSTRUCT|MUTCASE|FIX|COFIX)'>
<!-- CIC objects: -->
<!ELEMENT Definition (body, type)>
<!ATTLIST Definition
name CDATA #REQUIRED
params CDATA #REQUIRED
param_mode (POSSIBLE) #IMPLIED>
<!ELEMENT Axiom (type)>
<!ATTLIST Axiom
name CDATA #REQUIRED
params CDATA #REQUIRED>
<!ELEMENT CurrentProof (Conjecture*,body,type)>
<!ATTLIST CurrentProof
name CDATA #REQUIRED>
<!ELEMENT InductiveDefinition (InductiveType+)>
<!ATTLIST InductiveDefinition
noParams NMTOKEN #REQUIRED
params CDATA #REQUIRED>
<!ELEMENT Variable (type)>
<!ATTLIST Variable
name CDATA #REQUIRED>
<!-- Elements used in CIC objects, which are not terms: -->
<!ELEMENT InductiveType (arity,Constructor*)>
<!ATTLIST InductiveType
name CDATA #REQUIRED
inductive (true|false) #REQUIRED>
<!ELEMENT Conjecture %term;>
<!ATTLIST Conjecture
no NMTOKEN #REQUIRED>
<!ELEMENT Constructor %term;>
<!ATTLIST Constructor
id CDATA #REQUIRED>
<!-- CIC terms: -->
<!ELEMENT LAMBDA (source,target)>
<!ELEMENT PROD (source,target)>
<!ELEMENT CAST (term,type)>
<!ELEMENT REL EMPTY>
<!ATTLIST REL
value NMTOKEN #REQUIRED>
<!ELEMENT SORT EMPTY>
<!ATTLIST SORT
value CDATA #REQUIRED>
<!ELEMENT APPLY (%term;)+>
<!ELEMENT VAR EMPTY>
<!ATTLIST VAR
relUri CDATA #REQUIRED>
<!ELEMENT META EMPTY>
<!ATTLIST META
no NMTOKEN #REQUIRED>
<!ELEMENT IMPLICIT EMPTY>
<!ELEMENT CONST EMPTY>
<!ATTLIST CONST
uri CDATA #REQUIRED>
<!ELEMENT ABST EMPTY>
<!ATTLIST ABST
uri CDATA #REQUIRED>
<!ELEMENT MUTIND EMPTY>
<!ATTLIST MUTIND
uri CDATA #REQUIRED
noType NMTOKEN #REQUIRED>
<!ELEMENT MUTCONSTRUCT EMPTY>
<!ATTLIST MUTCONSTRUCT
uri CDATA #REQUIRED
noType NMTOKEN #REQUIRED
noConstr NMTOKEN #REQUIRED>
<!ELEMENT MUTCASE (patternsType,inductiveTerm,pattern*)>
<!ATTLIST MUTCASE
uriType CDATA #REQUIRED
noType NMTOKEN #REQUIRED>
<!ELEMENT FIX (FixFunction)+>
<!ATTLIST FIX
noFun NMTOKEN #REQUIRED>
<!ELEMENT COFIX (CofixFunction)+>
<!ATTLIST COFIX
noFun NMTOKEN #REQUIRED>
<!-- Elements used in CIC terms: -->
<!ELEMENT FixFunction (type,body)>
<!ATTLIST FixFunction
name CDATA #REQUIRED
recIndex NMTOKEN #REQUIRED>
<!ELEMENT CofixFunction (type,body)>
<!ATTLIST CofixFunction
name CDATA #REQUIRED>
<!-- Sintactic sugar for CIC terms and for CIC objects: -->
<!ELEMENT source %term;>
<!ELEMENT target %term;>
<!ATTLIST target
binder CDATA #IMPLIED>
<!ELEMENT term %term;>
<!ELEMENT type %term;>
<!ELEMENT patternsType %term;>
<!ELEMENT inductiveTerm %term;>
<!ELEMENT pattern %term;>
<!ELEMENT body %term;>
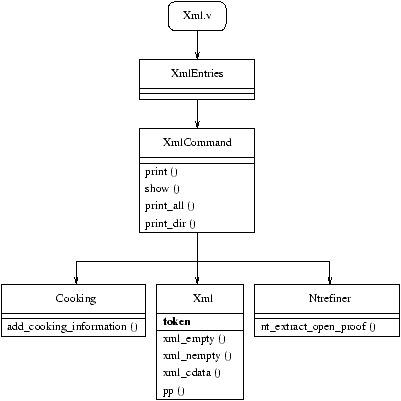
2.1.9 The code
We have firmly choosed not to modify Coq at all to export XML files. So we have
written a brand new ``tactic'' named Xml (to be stored in
tactics/contrib/xml). The tactic is very dependent on the internal
data structures of Coq, that are now changing version after version. So we hope
that the tactic will be accepted in the set of standard contributions to Coq
(so that it will be considered when modifing Coq's code). Once loaded via
``Require Xml.'', four new commands become availables to Coq users:
...SPIEGAZIONE DELLE TATTICHE
To implements these new commands we have written some OCaml modules and a
vernacular file Xml.v:
Figure 1:
Parsing
Once exported in XML, we need to parse CIC objects and
put them in memory in an internal, useful representation. While the XML
representation should be kept small and unredundant as much as possible
(redundancy means more space occupied and more consistency checks), the
internal representation is thought to fasten the subsequent accesses to the
information (e.g. duging typechecking), at the price of overloading the
parsing phase.
Our parser has been built using Markup. Markup is a generic validating XML
parser written by ??? entirely and from scratch in OCaml. Being a validating
XML parser, it is really fast (as fast as the nsgml parser written by J. Clarck
for SGML and faster than the validating XML parser XML::Parser ??? written in
Perl). Absolutely speaking, though, it is not too fast (it takes about six
minutes to parse all the standard library of Coq): this is due to the huge
dimensions of the XML files (the standard library of Coq is about 80Mb in
uncompress form and reduces to 3-4Mb once compressed) and perhaps also to
validation.
How to fasten parsing time
First of all, should we really need a validating XML parser? The first answer
seems to be yes because it is really important for a system like ours to be
able to detect errors. But in fact a lot of controls have subsequently been
added during parsing and will be in subsequently phases, up to type-checking
the entire proof. So, in next phases, when we'll have a clear view of how
heavy is parsing on the entire computation, we'll turn back and consider again
the use of a validating parser.
Another point is how much syntactic sugar should we put in XML files? Up to now
we have put a lot (50%) of syntactic sugar in XML files so that the files are
easily readable to anyone knowing CIC. For debugging purpouses this is great.
But, once finished, should XML files really be easily readable by humans? This
is one of the aims (a lesser one, thoug) of XML, but we must remember that in
CIC it doesn't exist a short proof: non trivial proofs are at least of some
hundreds of lines of XML and really very difficult to understand without a
proof-checker. It is also quite impossible to anyone to write a proof directly
in CIC without the help of a proof engine. So, in next phases, we'll reconsider
also if getting rid of the syntactic sugar.
The internal representation
Once parsed, the objects of CIC are stored internally using two concrete
data-types (term for the term level and obj for the object level)
whose constructors are chosen to match exactly the entities present in the
CIC DTD. Uris are all translated during parsing in absolute uris, even if
they
are encoded in the XML file as relative ones. In subsequent phases we will
need a fair elaborate data-structure for the uris to be able, for example,
to determine fastly if two uris are equal of if one uri is a prefix of another.
So we introduce an UriManager, i.e. an OCaml module declaring an abstract
data type uri and the functions to use it.
The code
Markup's main function takes in input the name of the xml file to parse, and
a bunch of options; then it parses and validates the file building the concrete
syntax tree that is returned. There are two possible ways to use the tree:
-
Functional style:
- the type of the concrete syntax tree is a concrete
data-type. So it is simple to write a bundle of recursive functions to
navigate the tree retrieving the information needed.
- Object Oriented style:
- it is possible to write a set of classes with
the same interface, instantiate each class to a clonable object called a
prototype and tell markup to link each node of the tree to a copy of
a particular prototype. The map from XML-element names to prototypes is
called a DOM in markup. Therefore, it is possible to access the tree
in an object-oriented way simply calling the methods of the objects linked
to each node of the tree.
None of the two solutions is better of the other:
The functional style takes less memory (no prototypes and objects) than
the object-oriented style, but it may be less efficient: the recursive
functions used to navigate the tree for each node of the tree must try to
match the XML-element name to decide what action should be performed. This
means a lot of string comparisons that are notoriously slow. In the
object-oriented style the string-matches are done only one, when choosing
which prototype to clone, and an hashtable is used to fasten the search.
Thereafter, for each method called, only a method (dynamic) dispatch is needed,
which is not so heavy. From the point of view of software engineering,
though, the object-oriented style seems preferable.
What we need is a parser able to translate the generic XML concrete syntax tree
to our internal representation of the same tree (defined in the OCaml module
Cic).
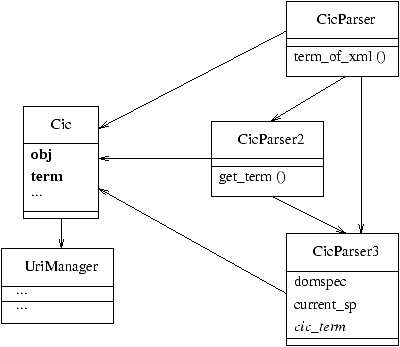
The dtd of CIC has two well-distinct levels: the level of the objects and that
of the terms. We have choosed to use the functional style when accessing the
object level (that has only few XML-element types) and the object-oriented
style when accessing the term level. So we have splitted the implementation of
the parser into three different modules:
-
CicParser
- The top-level parser. It's main functions, given the name
of an XML file containing a CIC object, returns the internal representation
of that object once parsed. This should be the only module accessed from
other OCaml modules; next two modules should be used directly only by this
one.
- CicParser2
- The object-level parser. In this module are defined the
recursive functions to convert the object-level nodes of markup trees to
the internal representation. It uses next module every time that one node
has a subnode at the terms level.
- CicParser3
- The term-level parser. It defines the DOM for translating
a term-level node of markup to the internal representation.
Figure 2:
aggiungere la spiegazione su come vengono risolte le uri relative
cambiare get_term in CicParser2 to get_obj
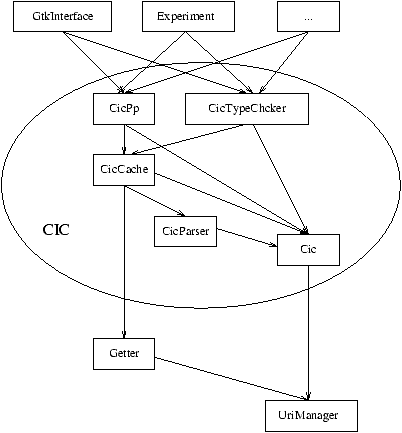
Overall architecture
Figure 3:
Figure 3 shows the overall architecture of helm at this phase.
At this early stage we consider only the
term and object levels, i.e. the single theorem, axiom, and so on. Obviously
we will need to build another level, the theory level, in which whole theories
(=structured sequences of theorems, axioms, etc.) will be taken into account.
As said, we want to isolate the modules depending on CIC in order to be able
to substitute easily the logical framework with another one.
At the top level we will have many interfaces to browse and
typecheck the single objects. Actually we plan at least to put together a
textual interface and a gtk interface. We require also that adding a brand
new top-level interface should be easy and should not require modifications
to lower-level modules.
Then we have some modules that are strictly dependent
on the logical framework: the pretty printer(s) (CicPp) will be able to
translate the internal format to something that could be used by the top-level
(mathml, for example). Probably many pretty printers will be developed. The
type-checker (CicTypeChecker) proof-checks objects once put in the internal
format. Every time one of these modules needs one object, it requires it to
the cache (CicCache). If a cache miss occurs, the cache is responsible to
ask the getter (Getter) to retrieve the XML file describing the object from
the Internet; once retrieved, the XML file is passed to the parser
that returns the internal representation of the object to be put into the
cache. As just said, the parser, the pretty-printer, the cache and the parser
depends heavily on the logical framework and on the internal representation
of it's objects, that will be described by the Cic module. Instead, the Getter
and the UriManager modules should be independent of the logical framework.
In order to test the parsing modules and to debug the tactic developed to
export terms from Coq, during this phase we have implemented all the remaining
modules (but the typechecker) in a trivial way: uris and filenames are the
same thing so that the getter actually does nothing at all and the UriManager
is easily coded. The cache is simply implemented as an hashtable (nothing is
never flushed from the cache). Finally the pretty-printer translates the
internal representation to the same textual description used by system Coq
and the two interfaces simply display that description, either in a terminal
(Experiment) or in a gtk text area (GtkInterface).