History, Advancements, and projectual choices.
The original idea of HELM goes back to the end of 1997.
Here is just the progress report starting november 1999.
November 2 1999
On the fragmentation of the library.
There is a main projectual choice concerning the degree of fragmentation
of the library. There are two extreme possibilities:
-
Big XML documents, corresponding, say, to typical libraries of proof assistant
applications (these are quite big, usually).
-
Very small documents, each one containing a single information "unit".
Here, there seem to be two main possibilities, according to what we consider
as a unit:
-
A document for each term;
-
A document for each definition (i.e. a pair of terms).
Solution 2 has two main advantages:
1. independent access to each information unit.
2. clear distinction between the "low" levels of the components of
the library (terms) and the "high" - or structural - levels (sections,
chapters, etc. ).
Let us discuss them. Having independent access to each information unit
could be a drawback in case the typical access follows some strong locality
pinciple. This is probably the case both for browsing (we would like to
"scroll" along some coherent piece of "theory"), and type-checking. However,
for type checking, a suitable caching mechanism could be probably enough,
while for browsing we are already making confusion between the term-level
and the structural one.
The idea is that at the term level we only have logical dependencies,
corresponding to pointers to other documents. These documents are collected
in a hierarchy of directories, reflecting their main structure. But nothing
prevenst to add more documents, e.g. metadata documents, for instance for
browsing purposes.
Metadata documents should (also?) describe how to structure a presentation
of the theory. They should be generated either manually (the user can change
the presentation of a theory) or automatically (from the .v files: the
presentation choice of the original author).
It seems plausible that the term and the structural level could be developed
in a quite independent way. In particular, the term level could (should?)
be independent from the higher levels. Of course, a term has (implicit)
information about its logical context (e.g. the "environment"). It is not
so clear if it could be worth to make explicit part of this implicit information.
Adding redundancy to the information raise the problem of preserving its
internal consistency.
Another point to be considered is that the decomposition in single information
units seems to go somewhat against the very nature of hypertextual documents.
In particular, the final aim is to avoid "anchors" inside a same file (although
some "anchors" would probably remain inside "mutual inductive" definitions).
This seems to be a bit contradictory with the choice of XML, and its features.
In other words we just use XML as a convenient (?) exchange format, and
little more.
Finally, the distinction between 2.1 and 2.2 does not seem to be a major
one. Probably 2.1 is better. Intermediate solutions between the two extremes
A and B do not seem to be particularly appealing.
November 26 1999.
Universes
The implicit handling of the level of Universes can be problematic. Here
is an example of two theorems which are both (independently) correct in
Coq, but whose "conjunction" is not...(!) Better, the two theorems cannot
be imported at the same time.
file definitions.v
Definition P := Type -> Type.
Definition Q := Type -> Type.
Definition p : P := [x:Type]x.
Definition q : Q := [x:Type]x.
file one.v
Require definitions.
Theorem easy1 : (a : (p Q))True.
Auto.
Qed.
file two.v
Require definitions.
Theorem easy2 : (a : (q P))True.
Auto.
Qed.
We have no solution at present. Probably, there is none: the user must
just be warned of this possible behaviour. Does the management of Universes
conflict with our Caching mechanism?
Access to data.
Regarding the fragmentation of the library, we have finally adopted solution
2.2. This raises some other concerns about the management of sections.
In Coq, we have two possible representations for objects defined inside
sections, namely cooked or uncooked. Roughly, cooking a term amounts to
abstracting the term w.r.t. its local variables; on the other side an uncooked
term is represented as a "receipe", that is essentially a closure.
Since sections can be nested, the same term has different representations
(views) at different nesting levels (possibly cooked or uncooked).
The "cooking" policy of COQ is far from clear.
Saving the library in XML, we would like to avoid to explicitly save
all the possible views of terms. The natural solution is to keep only the
definition at the deepest nesting level (i.e. the actual definition of
the term in its original section). However, this raises the question of
how to correctly access the term from outside this section (note that the
type changes according to the view).
For type-checking purposes, we need the ordered list of its free variables.
The problem is that by visiting the term (recursively on its constants),
we just obtain the UNORDERED list of its free variables. The only alternative
to add the explicit list to each definition was that of exporting the order
of definition of variables in the section. But this information is lees
convincing: it could exists also other sequences of definitions that are,
from the logical point of view, equivalent. So the exact order is only
an accident.
Actually, the problem looks more general, and in particular it concerns
the way we acces data in the system. COQ is mainly based on a functional
"style". When we close a section we export (some of) the local definitions
abstracting them w.r.t. the local variables. As a consequence, any time
we access the term from "the outside" we have to explicitly pass arguments
instantiating the "local" parameters.
We could imagine a discipline more akin to object oriented programming,
where we can for instance open a section instantiating (some of) the parameters
once and for all.
Does this eventually imply that we have to treat "sections" at the term
level of the language? (this is still open, at the moment).
Addressing Variables
Remark: We have the first version of the whd reduction algorithm!)
Another problem is the addressing of variables. In the current representation,
based on COQ, a variable is just a name Var(name); this contrasts with
axioms and constants, which are represented by a pair (section_path, name).
Section path is an absolute path; it essentially corresponds to our "Uniform
Resource Identifier (URI)" with the only difference that we also add the
"theory". For brevity, we shall use URI as a synonim of section path.
With our representation of the library, using just names for variables
looks a bit problematic. Every time we have to resolve a reference to a
variable we should visit the hierarchy of directories (sections) from the
section where the variable appears to the outermost one (quite heavy).
What is the drawback to access variables via URI, in the same way as
we do for constants? Well, in spite of axioms and constants, we have a
rigid discipline for accessing variables. In particular, from a given section
we can directly access variables declared in outermost sections, but not
e.g. in siblings. With an URI this is not evident. In other words, we should
add a consistency test. It is the usual problem: we are adding redundancy
in our representation, and we must guarantee its internal coherence.
There is a third solution, however: using relative URIS encoded in a
way that does not require any check. For example, instead of coding a variable
A defined in a super-super-section as a relative URI "../../A.var" and
check that the URI is well-formed according to the r.e. "(../)*{name}.var"
we could encode the URI in this obvious way: (2,"A.var"). This is not forbidden
by the RFC on URIs. The XML parser, than, should only check (as ever) that
the number is a right number. The benefit of this solution is to stress
the fact that some checks are performed on it.
Coming back to our representation of local terms in the previous section,
we had also a list of variables. This list is now a list of relatives URI's
(encoded as above, with integers).
Relative URI's are transformed in absolute ones during parsing. Having
an explicit list of absolute URI's does simplify our life in accessing
data "from outside", since we can easily recognize which variables are
to be considered as "abstracted" at the current level, and thus passed
as arguments.
Remark. Using receipes/cooked terms we have to do the previous
computation once and for all when closing the section. With our approach,
we must compute the "current view" of the term dynamically, each time we
access it. How heavy is this? The "cache" does not help here.
December 17 1999
We have the first version of the type-checker! Some aspects are still missing,
notably:
-
all "internal" checks on fixpoints, cofixpoints, inductive and coinductive
definitions, etc...
-
universes
The purpose of the current version of the type-checker was mainly to verify
that all relevant information was present in the low-level XML representation.
It is as simple as possible; in particular, perfomance has not be taken
into account.
A lot of problems have been pointed out:
-
Dummy parameters in inductive definitions. Dummy parameters are presented
in the CIC reference manual as syntactic sugar. Surprisingly, this "syntactic
sugar" generates two different internal representations!! (WHY!?!) As a
consequence, we need a function that, given the definition of the inductive
type, look if the parameter is dummy or not. (add details?). Question to
Coq people: why not exporting a flag which says if the parameter is dummy
or not?
-
Parameters and arguments. In CIC, there is a distinction between parameters
and arguments in inductive definitions. Initially, we tried to "guess"
this information from the actual definition of the inductive type. However,
we also need the same information during reduction, for mut_case (only
the list of arguments, not the parameters, are passed to the body of the
pattern). Our guess_arguments function is in the type-checker (and uses
the environment of the type-checker). It was difficult to integrate with
the reduction algorithm (which does not need such environment). Moreover,
this was going to create a mutual dependency between reduction and type-checking,
that we prefer to avoid. As a consequence, we now export in XML also the
number of parameters.
-
Fix and Cofix. During reduction (weak head), in order to preserve the termination
of type-checking, we have to expand a Fix only if its inductive argument
reduces to a constructor, and conversely expand a cofix only if it appears
as an argument of a mut_case. This is clear, now, but we overlooked the
point in the first draft; so it is worth to stress it.
-
Prop, Set and Type. In some cases, Prop and Set are convertible with Type.
For instance a function of type Type->Type can be applied to an element
of type Prop or Set. But a function of type Prop->Prop cannot be applied
to an element of type Type. In general, an element of type Type(i) is also
of Type(i+1). So, the conversion function is not commutative, and we should
change the order of parameters when we pass from a covariant to a controvariant
position. This is not implemented yet (as everything concerning universes).
At the moment, we identify all sorts.
-
Cooking This has been the most difficult part so far. Remember that we
cook "on the fly". Cooking a term amounts to abstract it w.r.t. its free
variables, and then scanning the term replacing each constant with an application
of the constant to the abstracted variable, in case the variable belongs
to the free variables of the constant.
The first problem is that "free" is a relative notion. I.e. if we are
cooking at a level defined by a given base URI, only variables below URI
should be taken into account. This is not particularly problematic, but
we have been forced to add the base URI as an explicit parameter to the
type-checker.
The second problem is that, so far, only some contstants had an explicit
list of parameters. In particular, local definition had none: since they
cannot be exported (and thus cannot be "cooked"), it seemed useless to
add the list. The problem is that local definition do appears in exported
ones: when cooking the exported definition, we need the list for the local
ones in order to understand if it must be transformed into an application
or not (things are even more complex in Coq, since we have odd notions
such as "local to the current and the above section"). So, every constant
must be equipped with its ordered list of free variables. Now, in order
to compute the list for non local definitions, our approach was the following
(this was done while exporting from Coq):
-
keep the ordered list of all variable declarations (potential parameters).
-
to each constant definition, associate the potential parameter to the constant.
-
when meeting (at the top level) the most kooked version of the definition,
trim the potential parameters w.r.t. the actual parameters (initial quantifications)
of the most cooked version (actually this approach also contains a bug,
since the less cooked definition may contain a "for all" on a variable
with the same name of a potential parameter; this bug was DIFFICULT to
track).
In any case, we cannot adopt a similar approach for local definitions,
since they are not cooked!
In the current version we fix the problem with a terrific "patch": we
associate to each local variable the "potential parameters"; then, at run
tine, we scan the constant to get the list of its free variables and trim
the potential parameters accordingly. This has been done just to check
the correctness of the type-checker. Eventually, we have to change our
strategy for exporting variables from Coq.
Some data
Finally, some data. The internal XML representation of the standard library
of Coq takes ~ 80 Mega (4 Mega after compression: they are all Tags). It
is pretty-printed, so a lot of space is taken by "blanks". Moreover, ~50%
of it is "syntactic sugar", for readibility purposes. Is it worth to go
towards a more compact representation? Maybe, but this topic looks a bit
marginal at present.
The type-checker is slow. More or less ten time slower than Coq (maybe
more). Remarkably, ~25% of the time is taken by the scanner (due to the
dimension of the files) and ~25% of the time is taken by the (validating)
XML parser.
January 10 2000
URI Manager
For modularity reasons, Uris's have been defined as an abstract datatype,
with a suitable module to access them (UriManager). We have tested several
different implementations for this module, with no major differences in
performance (the time gained in type-checking is essentially lost during
parsing). We shall probably retain the simplest one.
Local Definitions
The problem of variables for local definition described in the previous
report has been fixed.The code that deduce from the list
of possible occurring variables the list of actually occurring variables
has been moved from the type-checker to a brand new command that must be
used once and for all after the exporting of the local definition from
Coq. The aim of the new command is to parse the definition, compute the
list of occurring variables and write back the definition to XML. Hopefully,
interacting with the developers of Coq, it will be possible to get rid
of all this by exporting from Coq directly the list of actually occurring
variables.
Cooking
Cooking is now done once and for all the first time we ask
to typecheck some constant. The term is cooked at all possible levels,
which are stored in the cache. The improvement in performance, although
sensible, has been less impressive of what one could expect.
Getter
The getting mechanism has been entirely rewritten. Now we authomatically
contact a list of http (tested) and ftp (to be tested) sites, and all missing
files are downloaded. We use normal text file for exchange, and NDBM files
to access the local databes associating URL to URI. Still to be solved
(with Markus Mottl, author of Markup, the XML parser of OCaml) the problem
of getting for absolute URI's in XML files (external entities and dtd declarations).
January 21 2000
Good news on the performance issue!! A simple euristic (initial check for
structural equality during conversion) provided a drastical improvement
in performance. We are now comparable with COQ. HELM is on its way.
February 2 2000
A lot of improvements!!!
Internal representation
To cook the objects at every level only when we ask to type-check them
(see January 10 2000), we had to change the
internal representation of MutInd, MutConstruct, MutCase and Const, associating
to the uri of the object they refer to an integer that is the number of
times that the object must be cooked. So, for example, (Const "cic:/coq/INIT/Logic/not.con"
2) means the constant not cooked two times, i.e. the cooked constant not
whose base uri is "cic:/coq/".
Here we have a space optimization problem: for example, if an object
depends only on variables defined 4 levels and 7 levels above, then the
objects cooked 0 to 3 times and that cooked 4 to 6 times are identical
but for the number of times that an object is cooked in the above nodes
(MutInd, MutConstruct, MutCase and Const). So the simple term (Const "cic:/coq/INIT/Logic/not.con"
0) whose base uri is cic:/coq/INIT/Logic and that does not depend on any
variable, cooked one time becomes (Const "cic:/coq/INIT/Logic/not.con"
1). This means that we must store in cache terms that differ only for a
few inessential informations, wasting space.
In fact, in order to solve the problem we have to do nothing at all!
In fact, if an object O does not depend on variables one level above, thenevery
object on which O depends can't depend on any variable at that level, and
so is "equal" to the object cooked one time less, up to the new cooking
numbers. Since this number are used only during delta-reduction and when
fetching the type of cooked terms, it is not important that the numers
are the right one, but only that they refer to an object undercooked that
is essentially "equal" to the right one. So, in the starting example, we
can store in cache only the object cooked 0, 4 and 7 times.
A bigger example could help to understand: let's define the sum and
product of two natural numbers so that their uris are cic:/coq/INIT/Datatypes/sum.ind.xml
and cic:/coq/INIT/Datatypes/prod.ind.xml. The definition of prod uses the
definition of sum and neither one depends on any variable. So, once type-checked,
we store them in cache cooked only 0 times and we will return them when
they will be asked cooked n times, for each n. Now, let's define a new
constant foo whose uri is cic:/examples/foo.con.xml which depends on prod.
Obviously it depend on prod cooked 2 times. When, during type-checking,
we'll ask the type of the constructors of prod cooked 2 times, we'll get
a reference to sum cooked 0 times. But sum should be cooked 2 times, not
0! Neverthless, there is actually no real difference between sum cooked
0 and sum cooked 2 times, so the type-checking will not be affected at
all by this.
Type-checker
All the checks required, but that on universes, has been implemented. Some
definitions given in the Coq manual and in the availables papers on CIC
are outdated for Coq. So we have had a lot of troubles in finding the good
ones:
-
Strictly and weakly positiveness conditions for the constructors of
an inductive type:
-
The definitions given in Coq manuals are no more the ones used by Coq.
In fact, now it is possible to define a constructor for the inductive type
t that takes in input a parameter of type (t' x1 ... xn t x'1 ... x'n)
where t' is another inductive type iff t and t' fullfill some conditions.
These conditions seem to have been never documented, so we have directly
asked Hugo Herbelin for them.
-
Guarded by destructors and guarded by constructors conditions on Fix
and CoFix definitions:
-
The definitions are given in a paper of Eduardo Gimenez (which one???),
but only in the case of a single definition, without mutual recursion.
We have extended the definitions to the mutual case. Than we have found
out that Coq accepts an even wider set of definitions. We have then given
a new definition, but we are not sure if it is equivalent to the one of
system Coq, nor if the system is still logically consistent (but we strongly
believe so!)
Up to now, during type-checking, each time a Fix or a CoFix is met, we
check all the necessary conditions on it. During reduction it may be that
the Fix or CoFix is replicated, i.e. substituted for a DeBrujin index.
Then, when met a second time, all the checks are performed again, even
the ones that will be surely passed. It should be possible to add a flag
to each (Co)Fix, meaning if the checks have just been performed, but we
have not tryed this yet.
Some data
Even with the new checks, the type-checker is really fast. Actually, the
90% of the time is spent during parsing and cooking (that seems to take
no considerable time, less than 2%), and only the 10% of the time in the
real type-checking. It is still to be understood how the euristic will
behave when universes will be implemented.
CIC DTD
The DTD has been revised. In fact, only the names of some entities and
attributes have been changed. Now the naming choices are more clear and
omogeneus.
Interface
Up to now, the interface used was based on Gtk text widgets and we had
a pretty printer that, given a Cic term, returns a string with the same
ugly representation of Coq; the string was showed using the text widget.
Now we have a new very simple pretty-printer that, instead, of returning
a string representation of the term, outputs a MathML file defining, through
presentation markup, the same ugly presentation used before. We have also
a new Gtk widget, inherited from the textual one, that, given the name
of a file written in a subset of MathML, renders it. Actually, only mi,
mo, mfenced and mtext tags can be used.
Visually, the two interfaces, the old one and the new one, are indistinguishable.
The new interface is surely slower than the old one (the MathML file must
be parsed, actually via Markup), but to the user it seems as fast as before.
Now we are ready to split and start working in parallel: one group will
work on implementing from scratch a new Gtk widget to render MathML presentation
markup and interact with it; the other one will focus on writing a transformation
(via XSLT stylesheets) of Cic XML files into MathML content and presentation
markup. The results of the work of the two groups will replace the new
pretty printer and the small MathML Widget actually implemented. In the
meanwhile we'll add universes to the type-checker.
March 3 2000
Stylesheets
Now we have two kind of output associated via stylesheets to the CIC XML
files: the first one is a MathML file, in particular using MathML presentation
markup elements (eventually embedded in HTML), and the second one is a
HTML file. A scketch of the transformations on CIC XML files can be given
by the following schema:
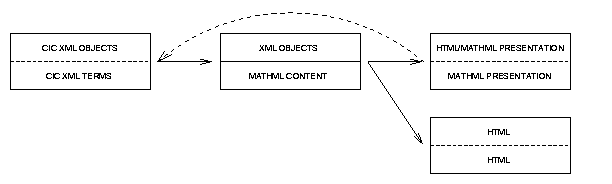
Figure 1: Transformations on CIC XML files: the backward
arrow means that the MathML presentation files can be modified and these
changes have effect also on the corresponding CIC XML files.
These two outputs are chosen in accordance with a cgi interface, passing
some variables to a particular stylesheet. This first transformation creates
in the CIC XML file the header for applying the right stylesheet. Then,
as you can see in the schema, there are two transformations via XSLT: the
first one produces MathML content markup and the second one produces either
MathML Presentation markup or HTML markup. We can note that the MathML
format can describe only CIC terms (expressions) and we have had to add
a second language to describe CIC objects in the intermediate step.
The Use of MathML presentation markup for rendering purposes is justified
by the aim of its specification consisting of providing a standard way
to enable mathematics to be served, received and processed on the world
wide web. On the contrary, the choice of having this intermediate format
of MathML content markup is justified by several reasons:
-
at this "semantic" level we can embed different theories coming from several
formal systems (codified by different XML formats);
-
MathML content markup, like the presentation markup, is intended to be
a standard for encoding mathematical content, so this characteristic of
portability can be useful to cut and paste terms from an environment to
another;
-
this level simplifies the structure of a CIC term: there is no more syntactic
sugar, but only "expressions";
-
at this level we can capture the semantic of particular terms, marking
them with more specific elements.
MathML limits
During the realization of the stylesheets, we have had to face and solve
several problems mainly connected to the MathML specification.
-
As we have said, MathML content elements don't describe objects like the
ones defined in CIC. CIC objects like definitions, axioms, proofs and variable
definitions, can be considered either like terms or expressions and thence
MathML elements, or part of the structure of the mathematical document
because they are typical of the CIC formal system and they haven't a general
meaning. The solution to this problem, has been adding to the MathML content
markup a XML level which describes the CIC objects in the intermediate
step (the eventual mixing will be possible using the W3C namespaces).
-
For most CIC terms there aren't specific MathML content markup elements,
since we are semantically describing particular terms of a formal system
instead of mathematical formulas. To fix this problem we are using the
"csymbol" markup, that is used for constructing a symbol whose semantic
is not part of the core content elements provided by MathML, but defined
externally. On the other hand, we'll produce, via stylesheets, specific
MathML content markup elements that may describe the corresponding mathematical
symbols defined in the extensions of the CIC language. These symbols, belonging
to a particular theory defined in the CIC formal system, can be better
described and rendered by the correspoding MathML elements.
-
Another problem strictly connected to the previous one regards the description
of the types. There isn't any MathML content feature to describe or assign
a type. We have had to introduce a provisional markup "type", out of the
MathML specification, to assign a type to a variable. Our next step will
be to remind to the MathML Working Group the importance of implementing
a set of content elements for describing at least the basic types of the
Type Theory and Set Theory and a feature to assign a type to a variable.
-
As you can see in the schema, we produce MathML content and presentation
in two distinct step. The only way to combine and link together content
and presentation in compliance to the MathML specification consists of
using the "semantics" element. This element is quite ambiguous for its
use, as a kind of "bridge" element between content and presentation, and
for this reason it isn't recognized by any browser implementing MathML.
This element will be ignored by our widget which try to render only its
first child throwing away the other children. In our opinion, the next
natural step for the MathML specification should consist of having content
and the associated presentations in different files (documents), one for
the content expression and one for each presentation. Then we need to have
links from a presentation expression and subexpressions to the respective
content expression and subexpressions. This can be achieved using the "id"
attribute and instead of the cross reference "xref", using the machinery
of Xlink. For instance, the already existent attribute "href" can be used
in a presentation element to fullfill this aim.
-
The above solution could make easier the implementation of the (hyper)links
for linking the original CIC XML terms to the content and presentation
corresponding elements. In this way the user can browse the HTML and the
MathML presentation files, and can also modify the MathML presentation
output and these changes will have effect on the corresponding CIC XML
file. As we have said above, this can be achieved using the machinery of
Xlink.
-
Finally, we have reckoned with the limits of the main tools implementing
MathML. We have not found a browser implementing the whole MathML reccomendation:
in fact we have even not found a browser able to render all the presentation
elements (and their attributes)!!! So, waiting implementations, we have
decided to produce also HTML pages with an applet inside to render the
presentation markup. The applet is the
WebEQ
one, that recognize almost all of the presentation elements, even if it
doesn't recognize all the attributes. In order not to download the applet
classes every time it is possible to "install" the applet downloading it
from the WebEQ site once and for all.
April 14 2000
Two different interfaces
We need to use XSLT stylesheets and MathML browsers, but:
-
There is no browser actually implementing the full XSLT reccomendation
-
There is no browser actually implementing the full MathML recoomendation
We also want any user with a web-space (either an http or an ftp one) to
be able to publish it's documents. So we have chosen to provide two diffente
interfaces to the library: the first one will be server based and will
require the XML publishing framework Cocoon (see
http://xml.apache.org)
on the server and a simple MathML aware browser on the client; the second
one will require a simple http or ftp server, but a fairly complex browser
on the client side able either to render MathML presentation markup and
to apply XSLT stylesheets to XML documents. This browser is the browser
we have been implementing.
Server side interface
The library is online! We are using Cocoon to apply the stylesheets, some
CGI to browse the library and do dirty tricks and some XSP to decouple
the XML files to the stylesheets that must be applied. Eventually, when
Cocoon 2.0 will be released, we won't need the XSP stuff any more.
Client side interface
A lot of changes! The code of the interface has been entirely rewritten
from scratch. During the development we have encountered a lot of problems
due to the binding of Gtk to OCaml. In particular some changes have been
done to the binding. Now we are trying to put our changes in the main distribution
In particular now we have a more powerful MathML widget and a brand
new bind to an XSLT processor:
MathML widget
We still don't have the real MathML widget (but we are working on it: up
to now we have written about 10.000 lines of C++ code). The small widget
we had built has been improved so that now it is possible to select a subexpression
or click on it. Selecting a subexpression means being able to get from
the widget an XPath individuating a node of the CIC DOM tree. The selection
(and so the clicking) are simulated (the user writes the XPath).
XSLT processor
Now that we have real stylesheets we need a real XSLT processor. There
isn't any one yet fully compliant with the reccomendation and written in
C, C++ or OCaml (for efficiency reasons). So we have chosen to use Xalan
(see
http://xml.apache.org) that is
written in Java (and is quite slow) because it will be ported (hoping soon)
to C++.
We can't load the JVM every time we need to process a file. Moreover,
reading and preprocessing our stylesheets require a lot of time to Xalan
(about 1 minute). So we have written a small UDP daemon that at startup
preprocesses the stylesheets and then waits for requests: a request specifyes
the name of the file on which the stylesheets must be applied. The daemon
applyes the stylesheet, writes the result on disk and answers the client.
The whole operation requires still too much time (a small theorem requires
up to 15 seconds to be processed). Using a cache is not maneageable (the
MathML files requires about 12 times the space of the original CIC files).
The only hope is waiting for the C++ porting
Annotations
The CIC DTD has been modified so that now every element could have an annotation
child. The client-side interface has been modified so that it now can be
used to annotate a term (actually writing in a text-field the XML content
of the annotation child). The stylesheets have been modified so that now,
if an element has an annotation, the annotation is displayed instead of
the term. Now we must develop two things:
-
A language for structuring annotations
Structuring an annotation means describing how annotations of subterms
can be used to annotate a superterm. For example an annotation of a lambda-abstraction
"\lambda P:Prop.T" could be " let P be a proposition. Then <sub/>" where
<sub> must be substituted during rendering (= application of the stylesheet
from CIC to MathML content) with the annotation of the subterm T (or with
the subterm itself if no annotation is provided)
-
A language for the annotations content
The annotations could not be only simple text. In particular they must
be written in a structured language where MathML could be embedded. The
right choose seems XHTML, but no decision has been taken yet.
May 8 2000
Configuration
Now there is an xml file in which we have put all the configuration
stuff. Now all the executables are easily installable on any machine,
but are still inherently single-user (for examples, what if two users
want to annotate the same file in different ways?). This has to be
addressed sooner or later.
Stylesheet for the theory level
Now we have also the first stylesheet for the theory level. The
time taken to apply the stylesheet even to simple theories is
really too high: about 2 minutes for a theory with about 20 objects.
May 12 2000
A lot of changes:
- The GtkMathView widget, yet not finished, has been integrated with
the client-side interface, replacing the dummy implementation.
It is yet not possible to easily select subexpressions.
- We have upgraded to the latest version of MathML DTD, that uses
also namespaces. We have had to modify all of ours DTDs and
XSLT-stylesheets.
- We have upgraded to the latest version of the DTD from
MathML-content to MathML-presentation. We have had to modify it,
too, because it's output does not use the MathML namespace yet (why?).
We'll have to modify it again in order to support our policy of
line-breaking long formulas
- We have two preliminary stylesheets to render even theories to
MathML or HTML. Using WebEQ to view the MathML rendered ones is
unfeaseable (due to the dimension of the rendered files).
- We have ported the code to OCaml-3.0: in fact no changes have been
required
- A new fairly-big theory (outside the standard library) developed by us has
been exported from Coq. Perhaps we'll try to annotate it.
May 26 2000
We have spent quite a lot of time in preparing a couple of articles
describing the current state of the project.
Some issues on the use of stylesheets
There are some interesting issues on the use of stylesheets that
are emerging.
- The case of "notin". The negation of "belongs to" and of other
mathematical relations are usually depicted by means of special symbols
(i.e. barring the positive symbol). On the other side, nothing forces
the declaration of "notin" as a new logical constant in the low level
specification. For instance, there is no declaration for notin in CIC
standard library. The translation we are looking for from CIC to MathML
content is thus something of the kind (not (in x A)) -->(notin x A).
This is not too difficult to implement with templates; the problem
is the definitionURL associated with notin: wehre should it point to?
- The case of "couple". In CIC, sets a represented as functions
from some universe U to Prop. If A is a set U->Prop, the property
that x belongs to A is just the application of A to x (this is the way
in is defined). So, (in x A) = (A x). The set of two elements x,y is
defined as a suitable inductive definition. Couple takes the two
elements of type U and gives back a set, i.e. a term of type U->Prop.
The sort of Couple is thus U->U->U->Prop. Properly, the set of
two elements x,y is just (Couple x y), but this is rarely used in CIC.
For instance, instead of writing (in z (Couple x y)) you just write
(Couple x y z). So we need two different templates for COUPLE,
according to the number of its argument. Moreover, if (Couple x y z)
is expanded to something of kind z x y
we have the problem to decide the DefinitionURL(s) and where to
put them (e.g. should we put it in the apply element, or in the
set element, or both?).
- The problem of parameters. There is an annoying problem related
to cooking. While cooking, we can add parameters. So, an occurrence
of a given term may have a different number of parameters according
to its position in the file hierarchy. For instance, most of the
operation on sets are defined in SETS/Ensemble/Ensemble and depend
on a variable U. As far as these operations are used inside
SETS/Ensemble/Ensemble, they do not need the extra-parameter U:
we just write, e.g., (In x A) or (Couple x y z). However, when we
use the same operations from the outside we must explicitly add
the parameter, writing something like (In U x A) or (Couple U x y z).
But then, how can we decide, in a stylesheet, if a term of the form
(Couple A B C) must be understood as "C belongs to {A,B}" and not
as the set {B,C} where A is the universe? In particular, we cannot
just rely on the number of the arguments (and other operations are
too complex to be performed by a stylesheet). At present, the most
natural solution seems to be the use a special application element
for "parameters" (or, more or less equivalently, adding a further
attribute to apply counting the number of parameters). This MUST
eventually be implemented.
- Notation depending on the TYPE of the term. A final problem
concerns the possibility of having notation depending on the type
of a term, and not only on the structure of the term. An example could
be the case of successions. A succession may be simply considered as
a function from nat into some metric space. So, the i-th element of
a succession "a" is just the application of a to i, but we would
probably prefer a notation like a_i (with a subscript). In order to
do so, we should recognize that a is of type succession, and not
a usual function. The problem has some similarities with the case
of in, in set. Even in this case, (in x A) could be simply written
(A x), due to the encoding of sets. Similarly, the problem of
successions could be solved by definining an operation "select"
such that (select i a) = (a i). In other words, there seems to be
some confusion between the implementation of a notion, and its
abstract definition (that eventually requires abstract operations).
If this is right, we probably do not need to provide mechanisms
for making the notation dependent from types. But maybe there
are more complex situations ...
Great changes in the client-side interface
- We are no more using MlGtk as the binding of OCaml to Gtk: we have
ported the code to LabelGtk that is a lot more developed. In this way
we need no more to modify the binding code to add unimplemented widgets
we need
- The MathView widget now supports hyperlinks: so it is possible
to browse the library jumping from a definition to another.
June 24 2000
Other time spent in preparing articles
describing the current state of the project.
Stylesheets:
- MathML Stylesheet:
we have "duplicated" the MathML stylesheet (mml2mmlv1_0.xsl) to take
in account the line-breaking policy for long expressions. When the
expression is not breaked, then mml2mmlv1_0.xsl is called.
- Constants: now to find the name of a constant we take the last part
of its URI (while before we opened the file corresponding to the constant
definition to retrieve the name).
This has been done to improve stylesheets performance.
- XREF pointer: we have added a pointer helm:xref
to point from the content file (expressions) and from
the presentation file (expressions) to the corresponding CIC XML file
(expressions). At first we have tried to use generic XPath expressions,
but we have a lot of ones and they were extremely long (up to some
thousands of characters for each one). So we have chosen to add an
unique attribute "id" to each CIC annotable node. Hence, now
the xref pointer is the id attribute value of the referenced CIC element.
These pointers are used by GtkMathView for implementing the selection: only
the rendered trees generated by an element with an xref attribute could be
selected and the selection actually is the content of the helm:xref attribute.
Here we have a problem: if we render a theory file concatenating all the
rendering of the objects of the theory, then the helm:xref pointers are
no more unique. The problem will be addressed when we'll return to work
on the theory level.
- Webeq bugs: Webeq does not implement the mchar elements (belonging
to the next MathML specification), so we have to translate them in
the corresponding entities. We do this in the CGI that create the HTML page
with the WebEQ applet. Moreover,
Webeq crashes when it find an mtext whose content is only spaces.
This kind of elements are generated by apply-templates calls without the
select attribute: now we avoid creating them. Moreover,
now the processing instruction of the presentation stylesheet generates XHTML
and no more HTML. We couldn't use the generic XML formatter because we do
not want to declare every MathML entity. Finally,
Webeq has some memory-leak: after a few (3/4) loaded files, it
hangs.
- New stylesheets: we have develope notation stylesheets for the
SET and REALS theories
- CGI files: WebEQ uses a non-standard extension to allow maction
elements to declare hyperlinks. This use of maction is a Webeq extension of
the suggested list of actiontypes, in compliance with the MathML specification.
We have add to the usual CGI file for WebEQ, the creation of maction XLinks
every time an xlink:href attribute is found.
In the future maction could be used in the rendering phase to switch among
different annotations associated to the same XML file (see actiontype=toggle)
- Annotations: now the annotations are in a different file with
respect to the corresponding CIC XML file. In this way we can have different
annotation files associated to the same XML file. The merging of the chosen
annotion with the annotated file is done before the stylesheets are applied.
Now this is done by an XSP page, but we are moving this feature inside the
getter (we are soon going to get rid of the XSP stuff).
- Identifiers: the Xslt id pattern cannot be used to match the id
attribute, because the parser,if not validating, is not able to
identify which attribute has an ID content. So we use the Xslt key feature,
that provide a way to work with documents containing an implicit
cross-references structure. In the header of a stylesheets we have to declare
the keys (name and value) for the elements matched with a pattern. There is
a function key(name,value) that return the node-set with the key "name" and
value "value".
- Annotations handling: A CIC file could have more than one
annotations: the user will be given in some way the choice on the annotation
used when looking at a single object.
With regard to the theory files, there
could be an annotation of the theory file in which is specified for every
CIC file what is the wanted annotation. Another choice could be
specifying also the annotations directly in the theory file.
June 29 2000
Due to serious hardware problems of our server, the library is no more
available on-line and we have to stop working on the on-line interface.
So, we'll focus on our interface while waiting for the new server.
January 15 2001
A lot of changes in all parts of project HELM, mainly due to the
availability of a new beta release for Coq:
- Module to export from XML: a new release of Coq, the V7.0,
is going to be released soon. So, the entire XML module has been
rewritten to work for V7.0 and is now part of the standard distribution
of Coq. The main difference with the previous release are:
- Inner types:
in order to produce better natural language
representation of proofs, we need to know the type of all the
subterms of the lambda-term. We call this types inner-types.
At first we have written a stylesheet to do type-inference in XSLT,
but the performances were really poor. Then we have decided to
compute this information inside Coq just during the extraction.
Now, every exported object (es. cic:/Coq/Init/Datatypes/nat.ind)
has a correspondant inner-types description
(es. cic:/Coq/Init/Datatypes/nat.ind.types). We use the identifiers
already introduced in object XML files for annotations to link
every inner-type to the corresponding subterm.
In order to reduce the size of the inner-types XML file,
we export only the types that will be used for natural language
rendering. So, for example, we avoid types of nested lambda-abstractions.
This is similar to consider nested lambda-abstractions as a single
lambda-abstraction with multiple binding. Other inner-types avoided
are the types of atomic subterms, i.e. constants or variable
references, constructors, etc. Finally, we avoid all the innery-types
whose type is not Prop.
- Sort/type attributes: in order to produce better natural
language representation of proofs, we need to know what is the
sort of all the term-level nodes of the lambda-term and the
type (which, actually, is a sort too) of all the type-level nodes.
For example, this information is used to decide if a Pi node
must be represented as a for-all symbol or as a Pi one.
This is a clear example of redundant information, but is a very
small one and difficult to get in XSLT (requires type-inference).
Moreover, it reduces the complexity of the check that determines
if an inner-type is linked to the current node during XSLT
execution.
- Primitive LetIn: a new LetIn node has been added to CIC in
Coq V7.0. Obviously, the export module does recognize it now.
Moreover, it is now possible to have variables with bodies, corresponding
to LetIn (variable without bodies still correspond to Pi/lambda
abstractions).
- DTDs: cic.dtd has changed to accomodate the new sort/type
attributes and the primitive LetIn constructor.
- Stylesheets: now identifiers ending with a number are
rendered as subscribed identifiers. This is the intended usage of
the final number in Coq, but seems to be not natural for constants
names. So, it is possible that it will be retained only for local
binders. We have still to accomodate the changes to the DTD.
- Natural language: ????????
- Perl Getter: Has been completely rewritten from scratch.
It is now possible to use it to syntethise documents starting
from the XML file, an optional XML inner-types file and an optional
XML annotation file. Moreover, we can now work with compressed XML files.
In this way, for example, the size of the V7 standard library plus some
of the contributions to V6.x that compiles under V7 has been reduced
from 289Mb to 38Mb !!!
- XALAND: we have fought for monthes with the new implementations
of Xalan-J that are all bugged or much slower than the first ones.
Only now it seems that we have a new release (Xalan-J2.0.D07) that is
both bug-free and faster than Xalan-J1. Thanks to the improvement in
Xalan performance, the adoption of the new Jdk1.3 and the rewriting
of the UDP daemon, we are now 400% faster on some big examples.
Moreover, we are trying a new architecture that makes easier applying
multiple stylesheets to the same document according to the pipeline
or waterfall model.
- Gtk Interface: we are now using a new version of the
LablGtk binding, a new version of the GtkMathView widget and
a new version of the Markup XML processor, now called PXP.
Moreover, we have addressed problems due to the management of Gtk
trees holding thousands of labels (one for all object in the library
now exported) using OCaml lazy code. In this way, the bootstrap of the
interface does take only 8s instead of the 74s that tooked before.
- Cocoon: no improvements here, but we are going to
update it to work with V7.0, too.
- First alpha release: we have worked also on packaging issues,
introducing autoconf to configure all the parts of the project and
building RPM packages. As a result, we have released our first alpha
version at the same time that the Coq team has released the first beta
version of Coq V7.0.
We are now working on performances, bug fixing and stability issues to
get a first beta release, that we hope will be available together with
the final version of Coq V7.0.